
 06-文本处理与正则表达式
06-文本处理与正则表达式
06-文本处理与正则表达式
文本编辑与查看
echo
前面提到的echo命令和cat命令都是可以用于文件编辑的命令,当然还包括前面提到的vi和vim编辑器。
echo是Linux中最常用的命令,常用于脚本编写、命令行输出和字符处理。
语法:
echo [选项] [变量值]或[文件]或[字符串]
-n:不输出结尾的换行符
-e:启用转义字符(如\n、\t等)
-E:禁用转义字符(默认行为)echo是支持特殊字符的,例如:
\n:换行符\t:制表符\\:反斜杠\":双引号\:单引号
案例如下:
我们直接使用echo来打印文本信息到终端中,操作如下:
miui@fedora:~$ echo "Hello, Linux!"
Hello, Linux!输出变量值,操作如下:
miui@fedora:~$ name=tiangesec
miui@fedora:~$ echo $name
tiangesec我们可以在输出信息的时候关闭换行操作:
miui@fedora:~$ echo "Hello,"
Hello,
miui@fedora:~$ echo "Linux!"
Linux!
miui@fedora:~$ echo -n "Hello,"
Hello,miui@fedora:~$ echo "Linux!"
Linux!还可以使用转译字符来实现换行操作:
miui@fedora:~$ echo -e "Hello\nLinux!"
Hello
Linux!我们使用-E选项,转译字符就不会被识别到,最后的结果就变成了这样:
miui@fedora:~$ echo -E "Hello\nWorld!"
Hello\nWorld!使用变量和文本混合输出:
miui@fedora:~$ name=Linux
miui@fedora:~$ echo "Hello, $name"
Hello, Linuxcat
cat命令主要用于查看文件内容、创建文件、文件合并等操作。和正常表达式、重定向搭配有奇效。
语法:
cat [选项]... [文件]...cat的自带选项使用并不频繁,这里就不列举了,我们可以使用--help选项来查看详细的用法。常见的用法如下:
我们可以使用cat命令来查看文件的内容,例如:
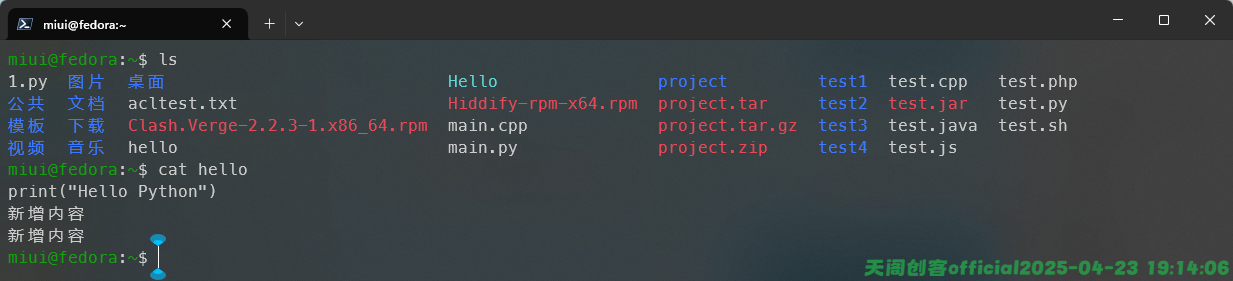
除此之外,我们也可以同时查看多个文件的内容,例如:
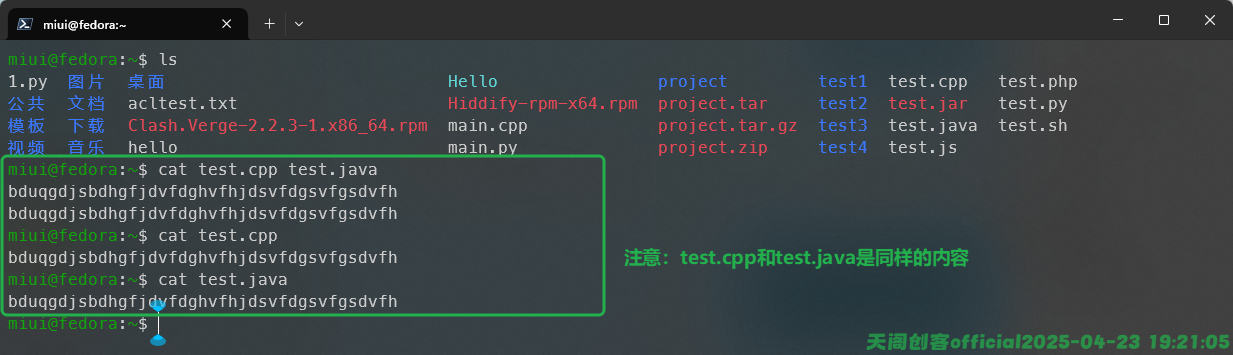
进阶玩法我们将在重定向和正则表达式的内容深入使用,这里不做深入讲解。
more
more命令可以一页一页地查看文件内容,就像看书一样,避免一次性输出大量文本导致信息太长阅读困难的问题。
语法:
more [选项] <文件>...
-d, --silent 显示帮助信息而非发出响铃提示音
-f, --logical 按逻辑行计数,而非按屏幕行计数
-l, --no-pause 抑制换页符后的暂停操作
-c, --print-over 不滚动屏幕,直接显示文本并清理行尾
-p, --clean-print 不滚动屏幕,先清理屏幕再显示文本
-e, --exit-on-eof 到达文件末尾时退出
-s, --squeeze 将多个连续的空行合并为一个空行
-u, --plain 不显示下划线和加粗效果
-n, --lines <数字> 每屏显示的行数
-<数字> 与 --lines 功能相同
+<数字> 从指定行号开始显示文件内容
+/<模式> 从匹配指定模式的行开始显示文件内容
-h, --help 显示此帮助信息
-V, --version 显示版本信息我们可以利用more来查看Linux中某个文件,例如我这里修改了test.py文件的内容,使用cat查看的时候就比较麻烦,看下面的Gif动图演示:
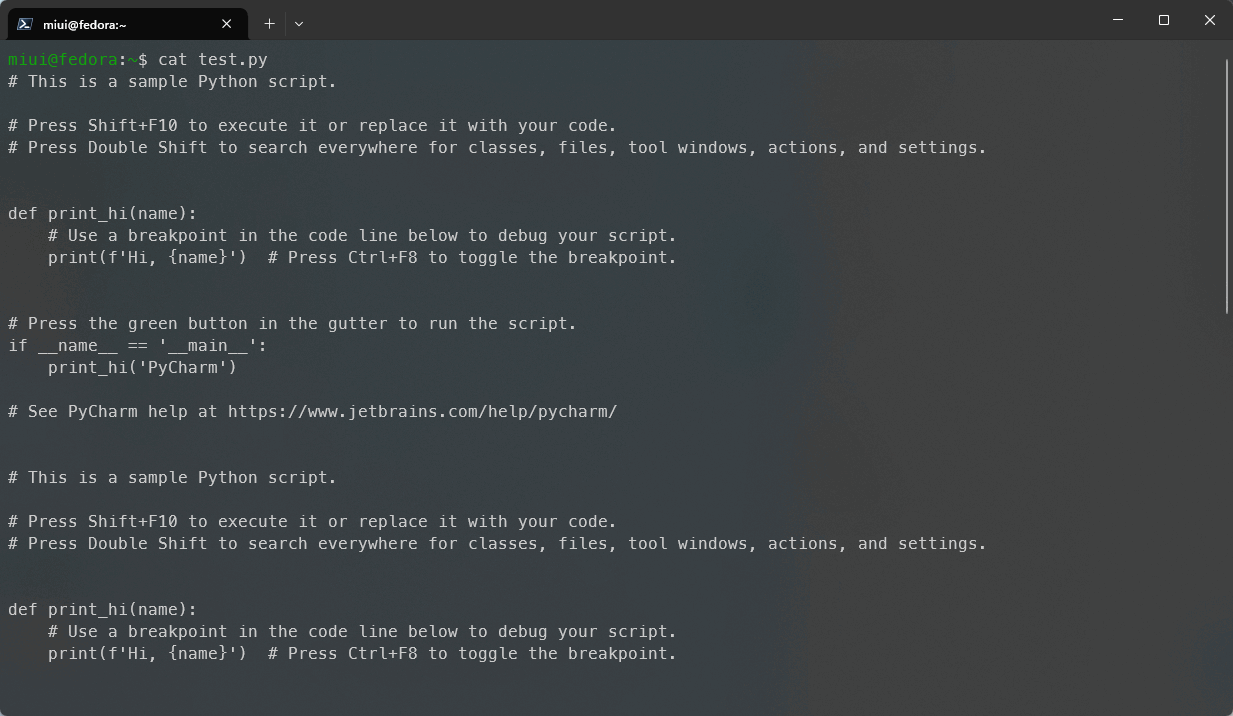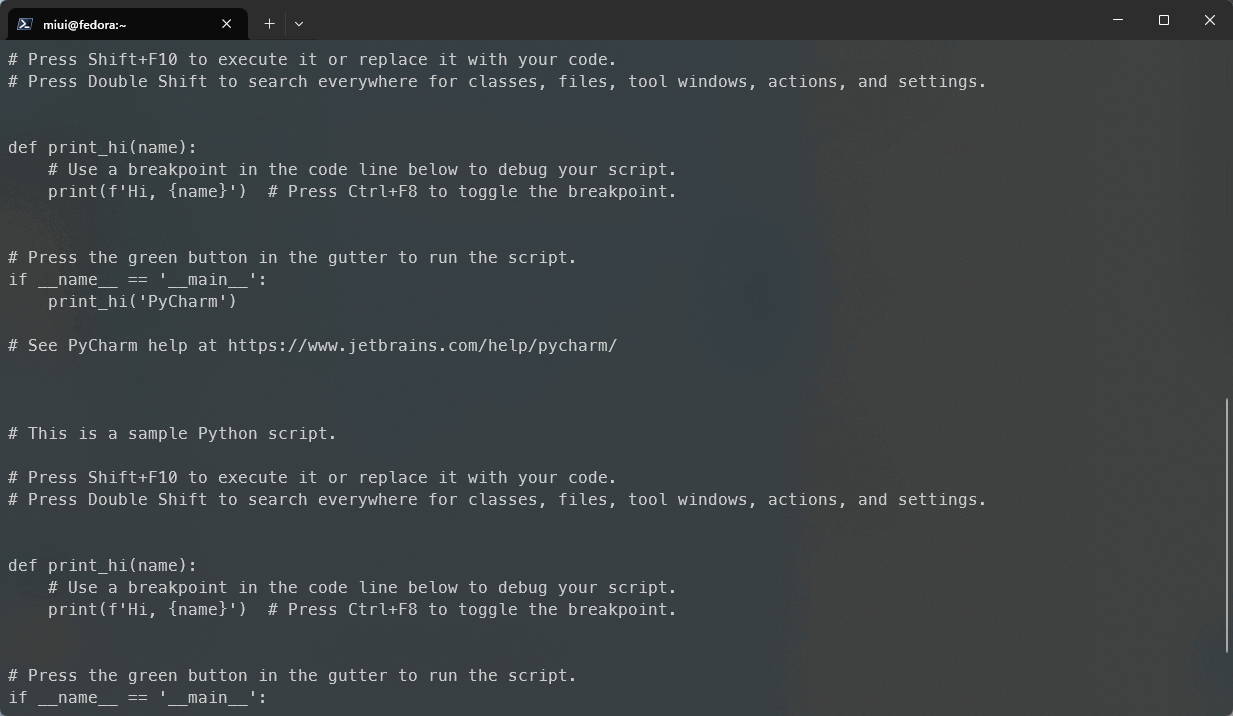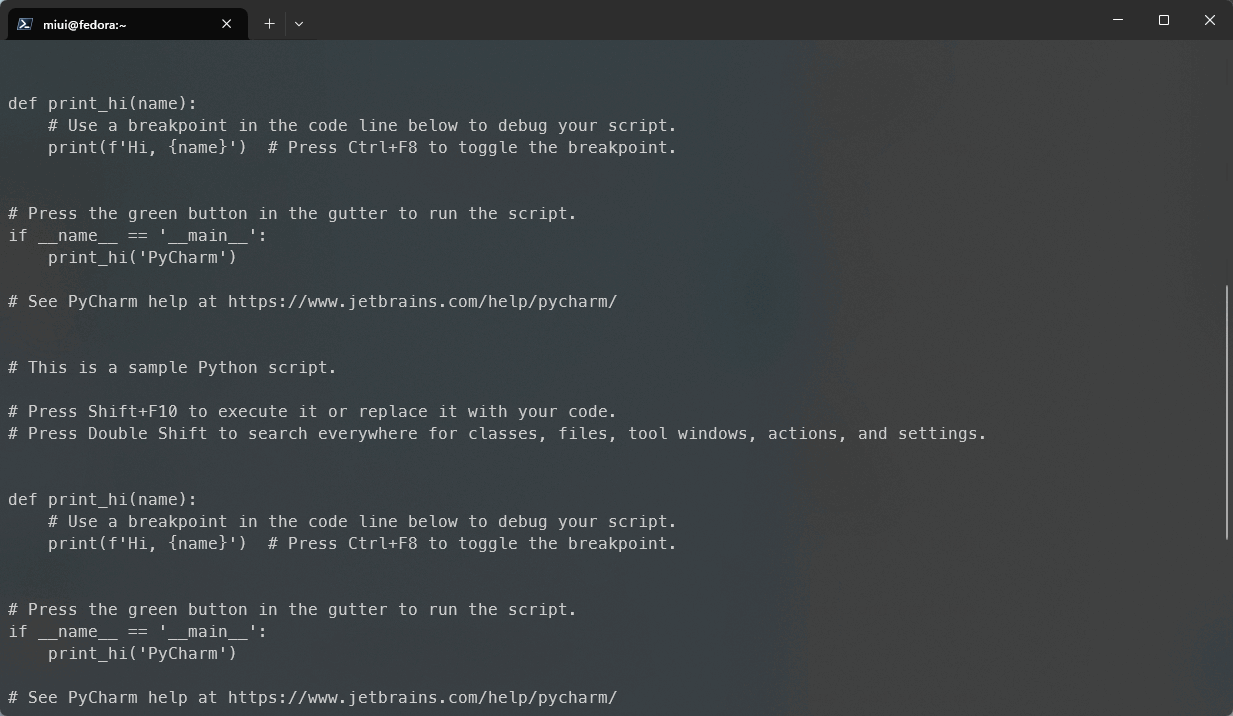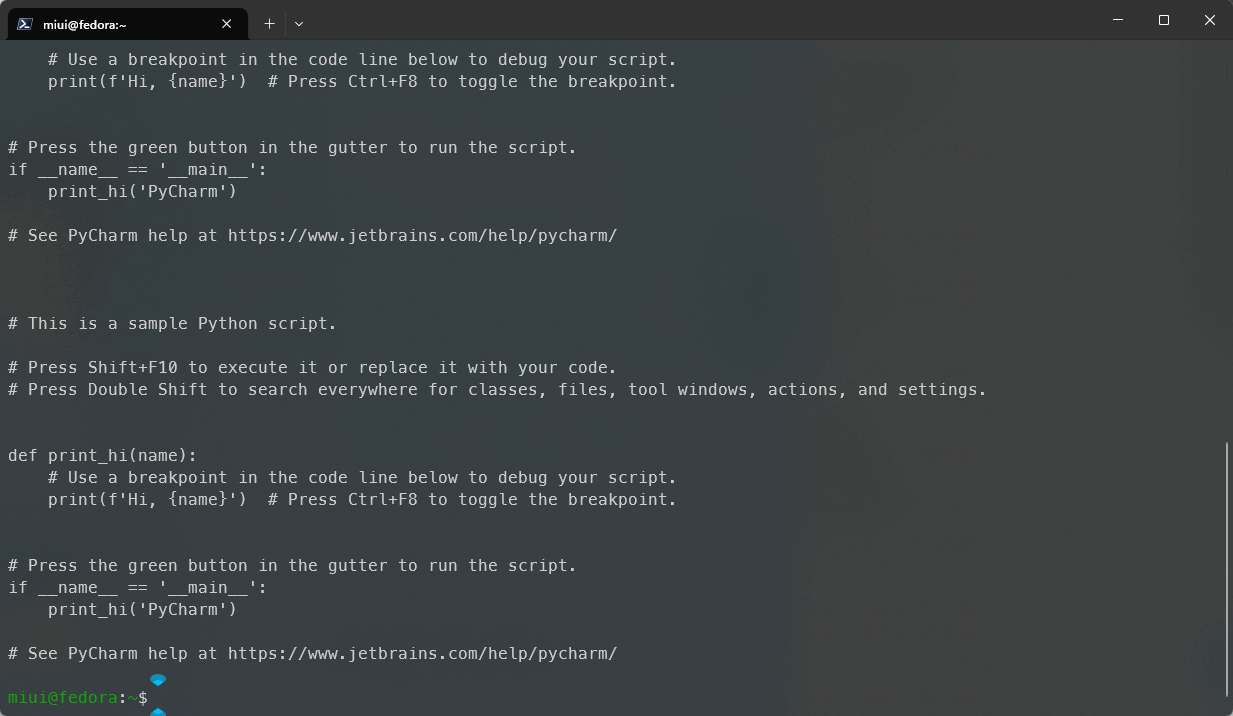
当文件内容过多的时候,cat命令就不适合阅读这样的文件,我们需要使用more或者其他的命令查看,我们这里尝试使用more来查看文件内容,如图:

这个时候我们可以使用上下按键实现来回阅读内容,一次是一页,空格键只能向下翻页,回车键只能一行一样阅读,当到最后一页的时候,左下角不会显示进度,直接会退出回到命令行。
如果不想查看内容,我们按住q键可以直接退出查看,或者Ctrl+C强制退出。
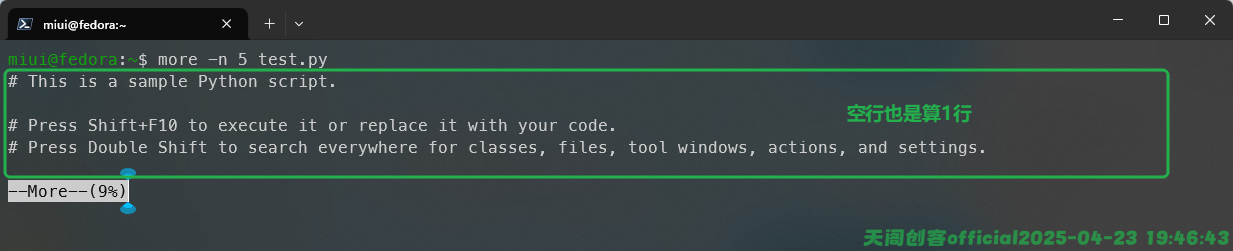
一页一页的阅读有时候还是会受到终端当前大小的影响,我们可以用-n选项配合数字的方式来控制每次显示的内容行数,这样可以更有效的阅读信息。如图:
我们还可以使用搜索功能,我们在进入阅读的时候按/键即可进入搜索模式,我们只需要在后门输入关键字即可,如果找到了,会自动跳转到匹配行,并且显示在屏幕顶部,我这里输入的是/Pycharm如图:
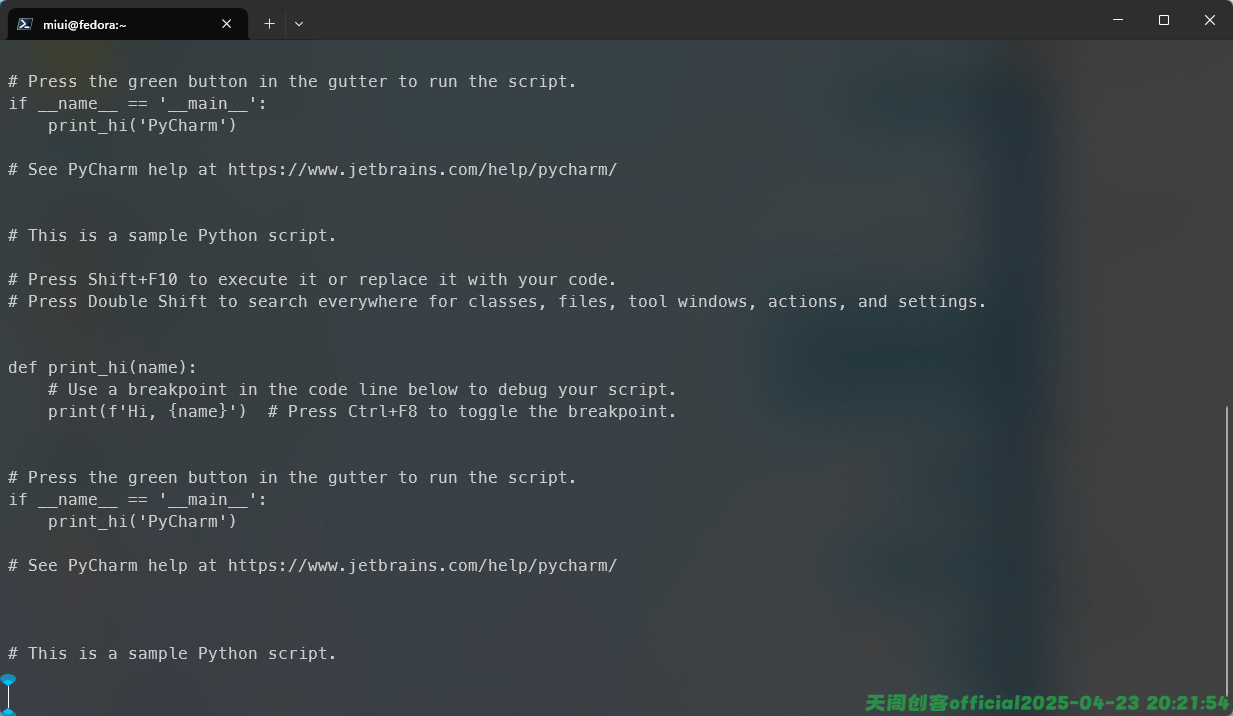
我们输入n的时候会继续查找下一个选项。
less
less命令是Linux中一个文本分页查看工具,主要用于查看长文件,和more命令类似,但是比more命令更强大,更灵活。
语法:
less [选项] <文件>...
-N, --LINE-NUMBERS 显示行号
-S, --chop-long-lines 不自动换行,长行截断显示(可用左右键查看)
-i, --ignore-case 搜索时忽略大小写(智能:仅当搜索词有大写时区分)
-I, --IGNORE-CASE-ALL 搜索时完全忽略大小写
-R, --RAW-CONTROL-CHARS 显示 ANSI 控制字符(保留颜色),常用于彩色日志
-F, --quit-if-one-screen 若文件内容不足一屏则自动退出
-X, --no-init 不清屏,退出 less 后保留内容(少用)
-g, --hilite-search 每次搜索仅高亮当前匹配项
-G, --HILITE-SEARCH 不高亮任何搜索匹配
-w, --hilite-until-repl 搜索高亮直到下次搜索
-m, --long-prompt 使用更详细的提示符(含行号、百分比)
-M, --LONG-PROMPT 更详细的提示符(增强版)
-d, --dumb 禁用高亮、加粗等显示特性
-p <模式> 启动后立即搜索该模式,并跳转到匹配位置
+/<模式> 启动后从首次匹配模式的位置开始显示
+<数字> 启动后从指定行号开始显示
-? , --help 显示帮助信息
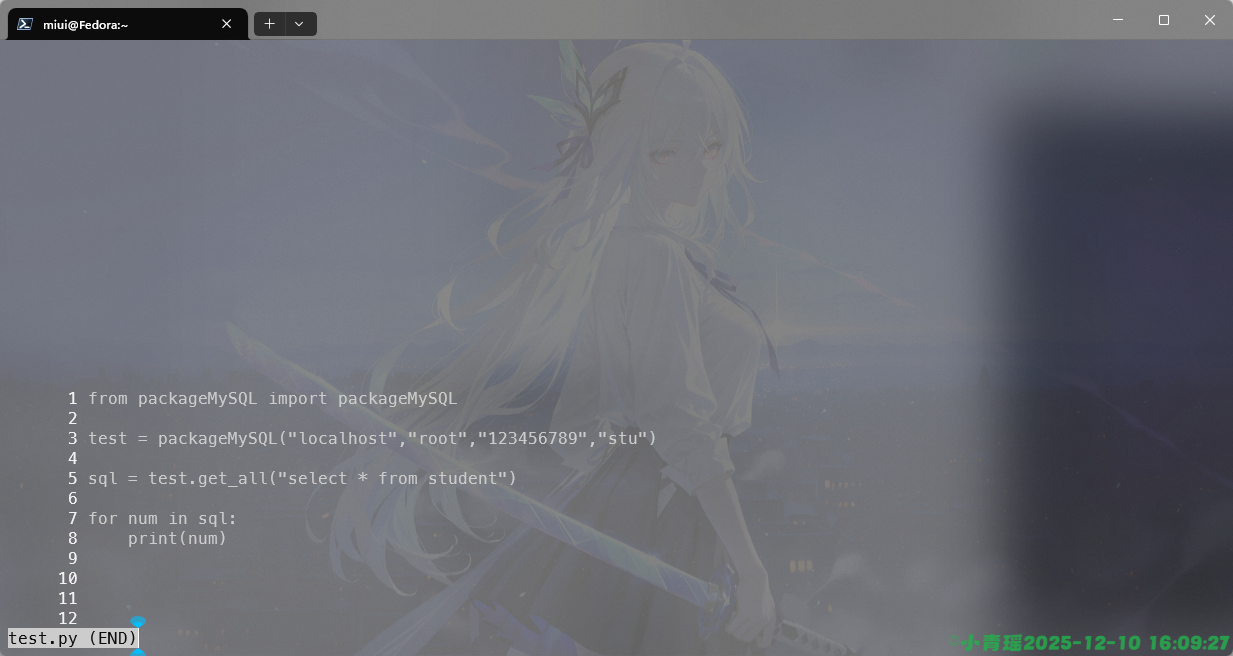
-V, --version 显示版本信息我们使用less -N的时候可以显示行号来查看文本信息,如图:
查看文本的时候可以使用键盘进行交互操作,例如:
交互操作:
空格 下一页
b 上一页
g 跳至文件开头
G 跳至文件末尾
/<模式> 向下搜索
?<模式> 向上搜索
n 下一个匹配
N 上一个匹配
q 退出 less
= 显示行号拓展:管道|
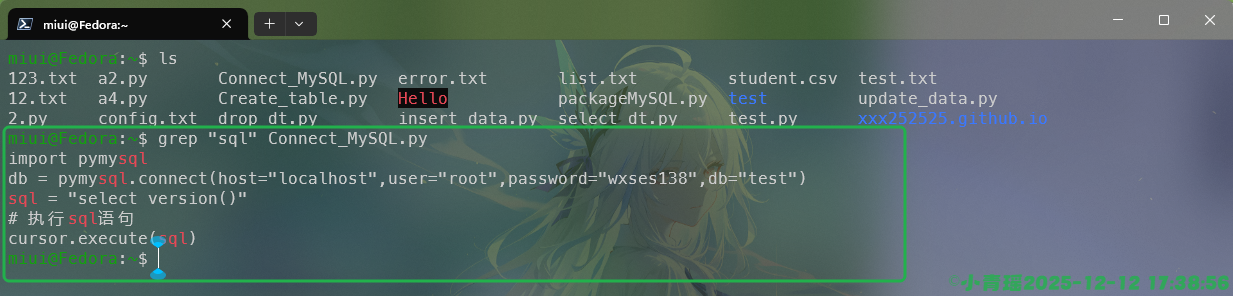
我们在学习文本处理的时候经常会使用到管道符号,也就是|,通常与各大命令配合使用,尤其是在过滤信息上面的时候非常有用。
例如我们可以使用|与grep来过滤sql这个字符串信息,只查看带有sql字符串的内容,如图:
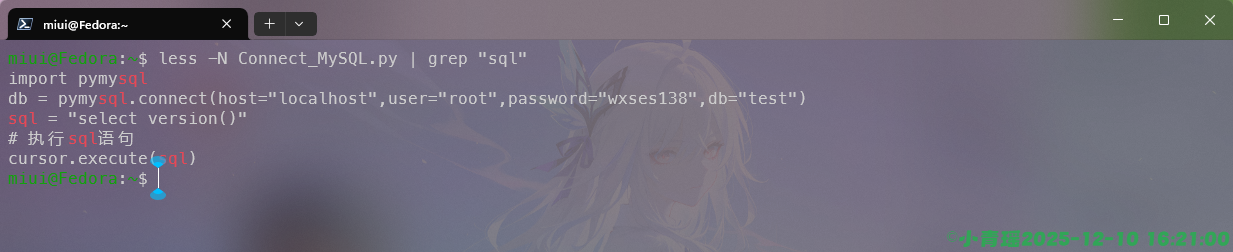
grep命令是我们后面要学习文件处理三剑客的内容这里不做展开。
head
head命令用于显示文件开头的内容,默认显示前面十行的内容
语法:
head [选项]... [文件]...
-c, --bytes=[-]数字 显示每个文件的前 <数字> 字节内容;
如果数字前附加 "-" 字符,则显示每个文件
除了最后 <数字> 字节以外的全部内容
-n, --lines=[-]数字 显示每个文件的前 <数字> 行内容而非前 10 行内容;
如果数字前附加 "-" 字符,则显示每个文件
除了最后 <数字> 行以外的全部内容
-q, --quiet, --silent 不打印文件名作为头部
-v, --verbose 总是打印文件名作为头部
-z, --zero-terminated 以 NUL 空字符而非换行符作为行分隔符
--help 显示此帮助信息并退出
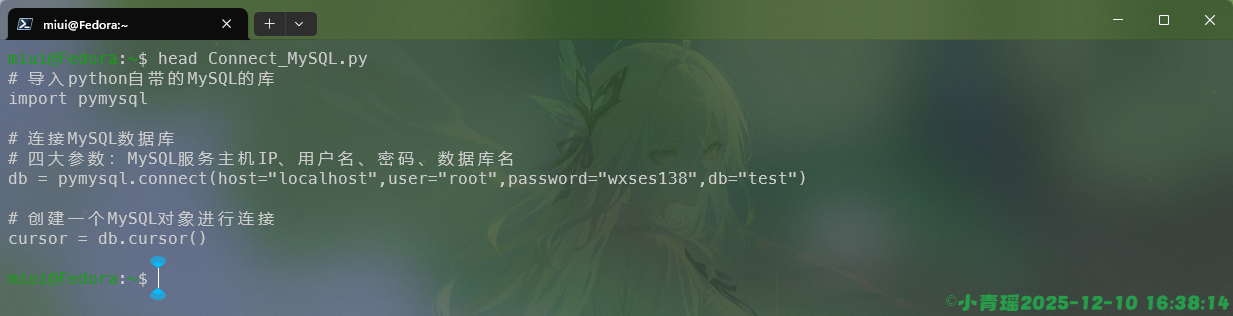
--version 显示版本信息并退出使用head命令查看文件内容,如下:
使用-n数字或者–lines=数字,查看固定行数内容,如图:

使用--bytes=数字查看固定字节的内容,如图:

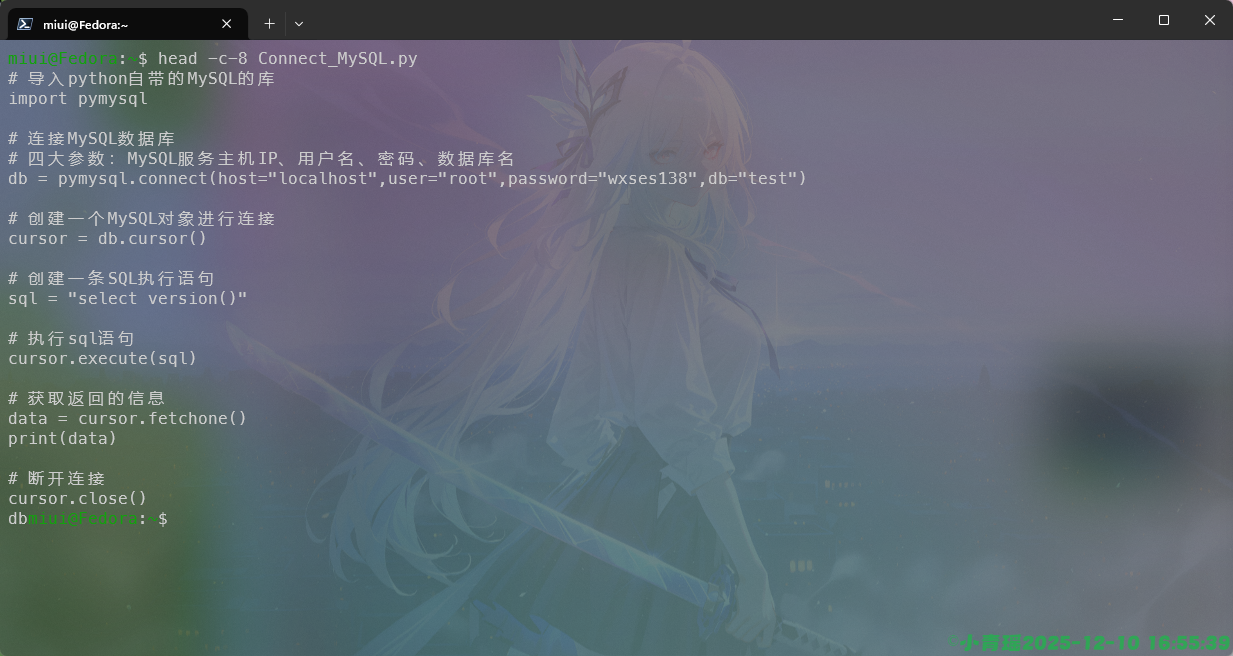
显示的内容是“# 导入”,就是八个字节,因为一个汉字是两个字节,一个英文字符是一个字节;不同编码格式不一样。使用-c8和–bytes=8的效果是一样的

如果在数字的前面添加-,除了最后个字符不会显示,其他都会显示,如图:
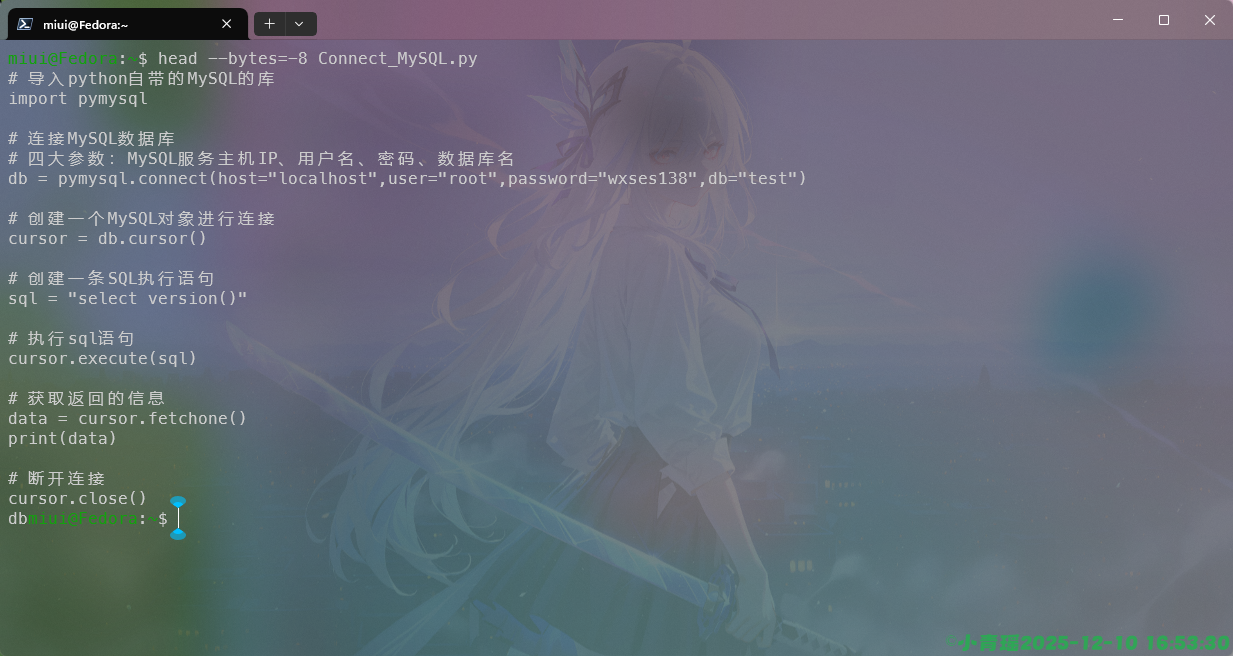
使用head -c-8是一模一样的显示效果。
注
<数字> 后面可以加上乘数后缀:
K, M, G(1024 制)
k, m, g(1000 制)
b = ×512
如果指定了多个 <文件>,程序会在每个文件的开头添加文件名作为头部;如果没有指定 <文件>,或者 <文件> 为 "-",则从标准输入读取。
tail
tail命令用于查看文件末尾部分的内容,默认显示最后的十行。经常用户查看日志的实时变化和监控程序的售出。
语法:
用法:tail [选项]... [文件]...
-c, --bytes=[+]数字 输出最后 <数字> 个字节;或者使用 -c +数字 以输出
每个文件第 <数字> 个字节起的全部内容
-f, --follow[={name|descriptor}]
随文件增长即时输出新增数据;
若未指定选项参数,则默认使用 "descriptor"
-F 同 --follow=name --retry
-n, --lines=[+]数字 输出最后 <数字> 行,而不是默认的最后 10 行;或者
使用 -n +数字 输出每个文件第 <数字> 行起的全部内容
--max-unchanged-stats=N
和 --follow=name 同时使用时, 如果一个 <文件> 在 N 次
(默认为 5 次)迭代后没有改变大小,则重新打开它,
以确认它是否已被删除或重命名(对于轮转 (rotated)
日志文件而言,这种情况很常见);
如果内核支持 inotify,则此选项通常没有用处
--pid=PID 和 -f 同时使用时,在进程号为 PID 的进程结束后终止执行
-q, --quiet, --silent 不输出含有文件名的头
--retry 即使目标文件无法访问,仍然不断尝试打开
-s, --sleep-interval=N 和 -f 同时使用时,在两次迭代之间睡眠约 N 秒
(默认 1.0 秒)
内核支持 inotify 且使用了 --pid=P 时,每 N 秒
至少检查一次进程 P
-v, --verbose 总是输出含有文件名的头
-z, --zero-terminated 以 NUL 空字符而非换行符作为行分隔符
--help 显示此帮助信息并退出
--version 显示版本信息并退出使用tail可以查看文件末尾十行的内容,如图:

tail和head命令的字符控制与行号控制的方式是一样的。使用-c数字和–bytes=数字内容如下:

注
<数字> 后面可以加上乘数后缀:
K, M, G(1024 制)
k, m, g(1000 制)
b = ×512
显示最后五行信息,如图:

实时跟踪文件内容更新(常用于看日志),使用-f, --follow[={name|descriptor}]即可,如图:
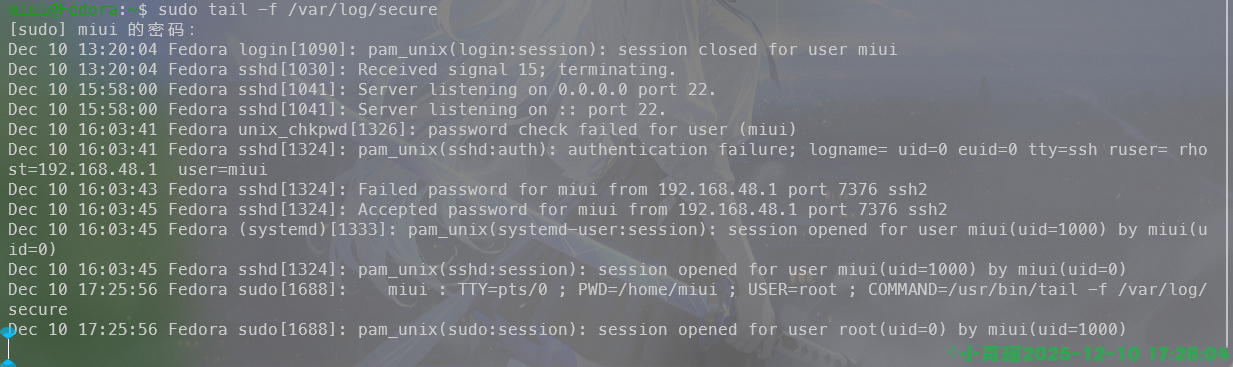
跟踪文件名(适合日志轮转)
sudo tail --follow=name /var/log/secure跟踪文件描述符(默认方式)
sudo tail --follow=descriptor /var/log/secure如图:
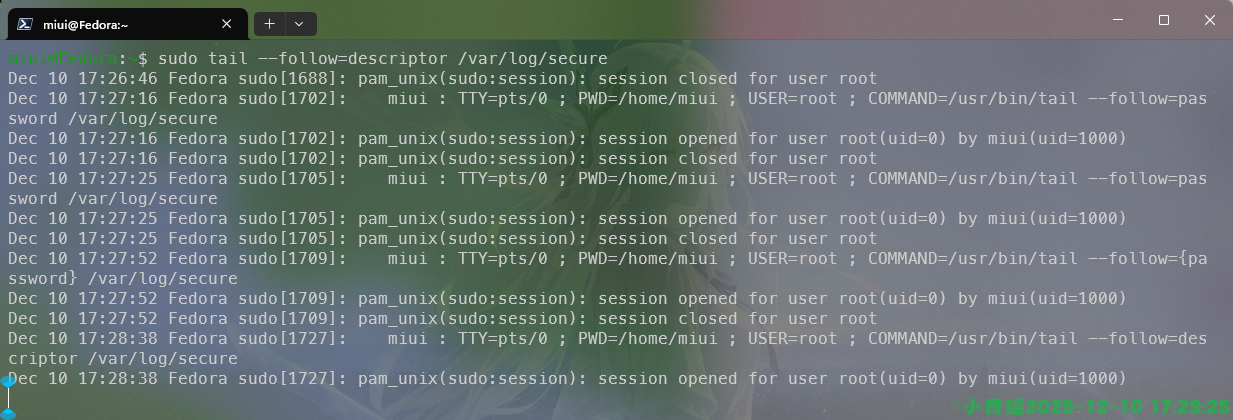 更强的实时监控,使用
更强的实时监控,使用-F 即可,日志切换也能持续监控,如图:
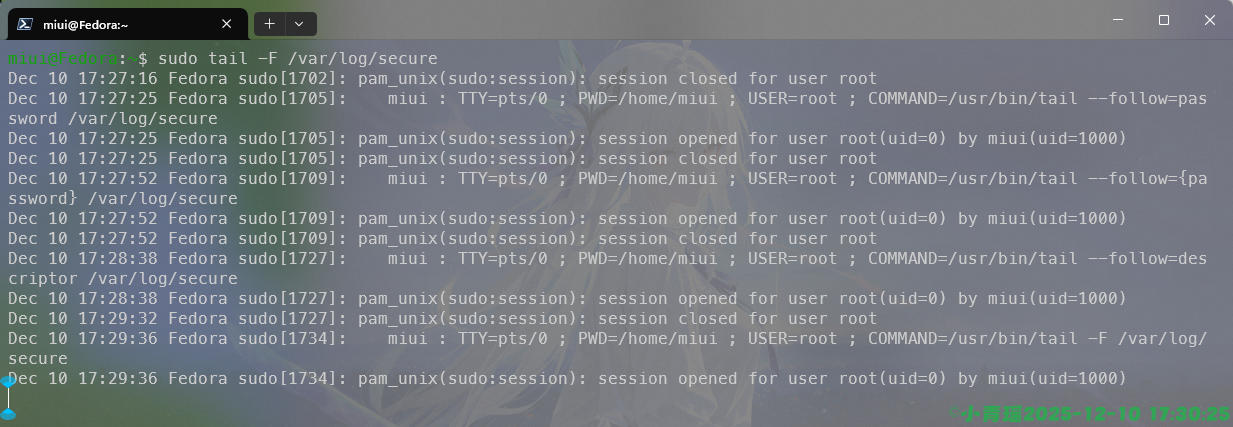
tac
tac是 cat 的反向版,主要功能是:倒序输出文件内容(从最后一行到第一行)
语法:
tac [选项]... [文件]...
-b, --before 在行首而非行尾添加分隔符
-r, --regex 将分隔符视为正则表达式进行解释
-s, --separator=字符串 使用 <字符串> 而非换行符作为行分隔符
--help 显示此帮助信息并退出
--version 显示版本信息并退出我们如果要倒序查看文件的时候就可以使用到tac,如图:
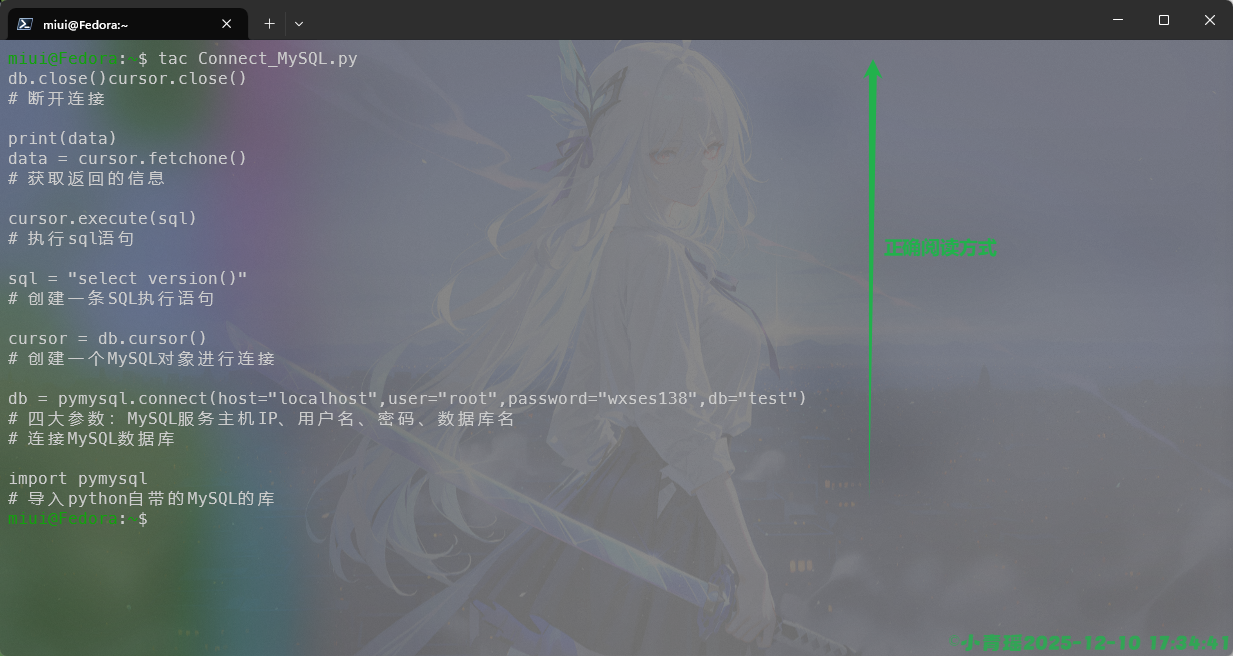
文本分析与统计
wc
wc命令用于统计文本或者输入文本的行数、单词数、字节数、字符数、最长行长度。
语法:
wc [选项]... [文件]...
或:wc [选项]... --files0-from=F
-c, --bytes 输出字节数
-m, --chars 输出字符数
-l, --lines 输出换行符数
--files0-from=F 从文件 F 中读取以 NUL 空字符分隔的文件名作为
输入文件的名称;
如果 F 是 "-",则从标准输入读取文件名
-L, --max-line-length 输出最长行的长度
-w, --words 输出单词数
--total=何时 何时打印含有 "总计" 的行;
<何时> 可以是:auto、always、only、never
--help 显示此帮助信息并退出
--version 显示版本信息并退出使用wc命令可以统计文件的信息,如下:

如果我们只统计行数,只需要在命令中添加选项-l即可,如图:
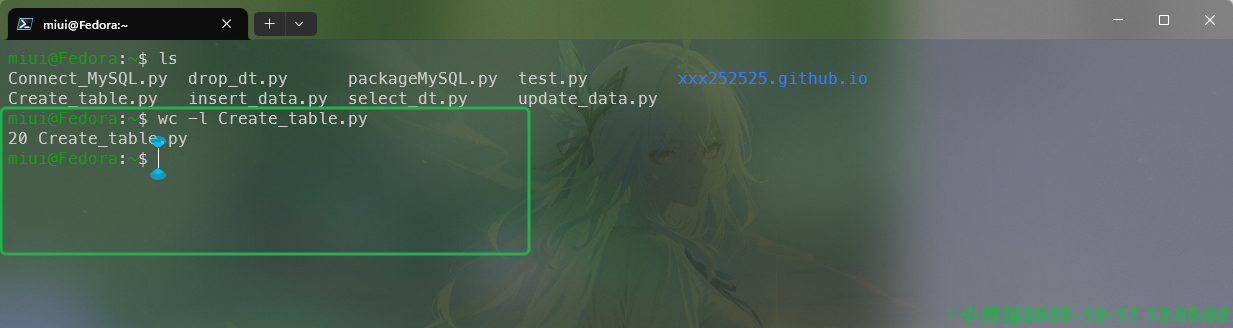
单纯想要统计字节数的话可以使用-c选项,如图:

当我们使用UTF-8的格式来统计字符的时候,可以使用如下操作:

警告
注意:-c与-m的区别。
前者是计算文件中实际的字节数,中文UTF-8一般是三个字节;后者是按照字符进行统计,哪怕是三个字节的中文也算一个字符。
实例,统计当前目录中所有的文件总行数,操作如下:

统计日志中匹配到的行数,操作如下:
sudo wc -l | grep "error" /var/log/securesort
sort命令用于给文本的内容进行一个排序,通常可以按照字典序、数字、列、月份等方式进行排序。
语法:
sort [选项]... [文件]...
或:sort [选项]... --files0-from=F
-h, --human-numeric-sort 对可读性较好的数字(例如:2K 1G)进行排序
-n, --numeric-sort 对数字进行排序
-R, --random-sort 随机排序,但是相等的键会排序到一起。参见 shuf(1)
--random-source=文件 从 <文件> 中获得随机字节
-r, --reverse 逆序输出排序结果
--sort=关键字 按照 <关键字> 指定的方式排序:
general-numeric 同 -g、human-numeric 同 -h、
month 同 -M、numeric 同 -n、random 同 -R、
version 同 -V
-t, --field-separator=分隔符 使用 <分隔符> 而不是非空白字符到空白字符的转变
作为字段分隔符
-T, --temporary-directory=目录 使用 <目录> 而非 $TMPDIR 或 /tmp 存放临时文件;
重复使用此选项可指定多个目录默认情况下使用sort命令进行的是字典序的排序,如图:
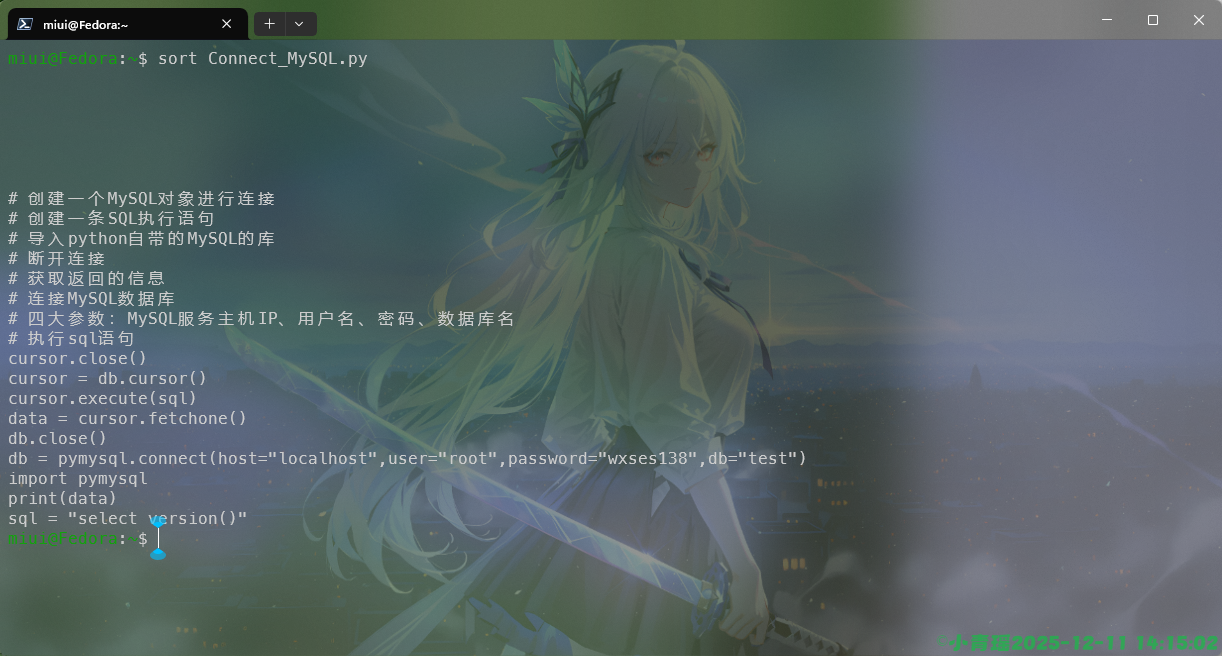
代码中的空行全部放在最前面去了。
我们一般使用的都是数字排序,如下操作:

源文件的内容是这样的:

我们可以看到,在进行排序的时候字典序的排序是从阿拉伯数字从小到大开始排序的,然后是英文字符,数字排序会把相同数字的排列在一起,我们使用-nr的时候可以实现一个倒序排序。如图:
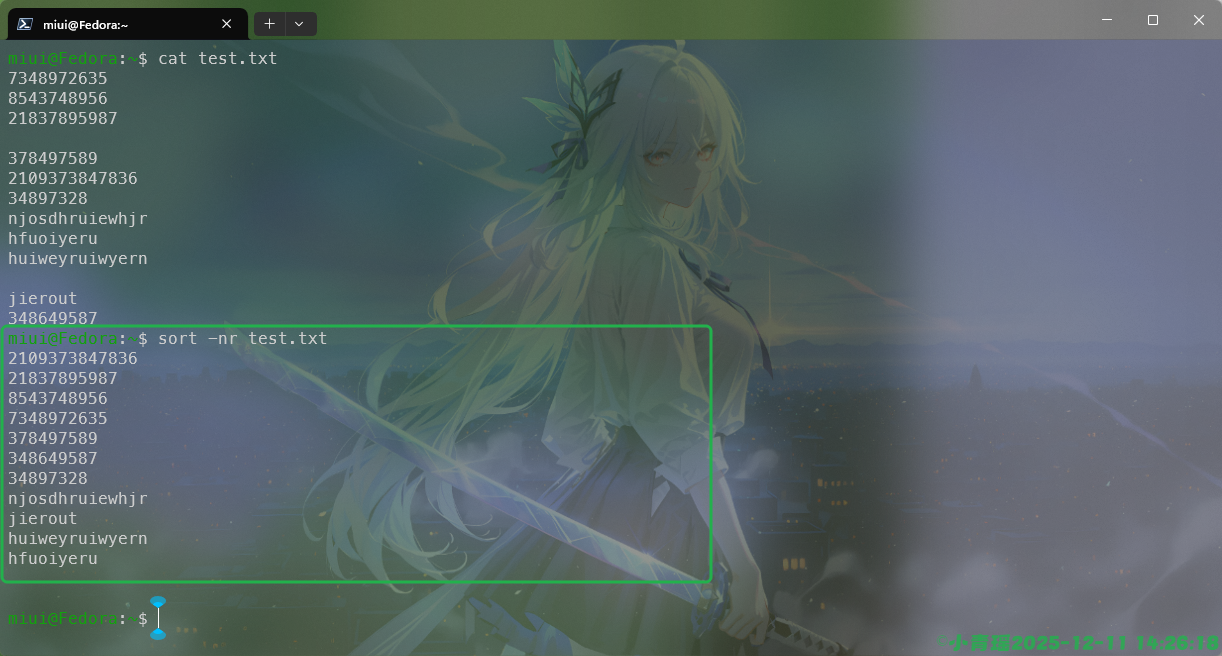
cut
cut命令用于从文本中截取内容,将数据抽出,一般用于日志的处理,可以按照字节、字符或者字段来进行截取
语法:
cut [选项] [文件]
-b, --bytes=列表 只选中指定的这些字节
-c, --characters=列表 只选中指定的这些字符
-d, --delimiter=分隔符 使用 <分隔符> 而不是 TAB 作为字段分隔符
-f, --fields=LIST select only these fields; also print any line
that contains no delimiter character, unless
the -s option is specified
-n with -b: don't split multibyte characters
--complement 对选中的字节、字符或字段的集合求补集
-s, --only-delimited 不打印不包含分隔符的行
--output-delimiter=字符串 使用 <字符串> 作为输出分隔符
默认值是使用输入分隔符
-z, --zero-terminated 以 NUL 空字符而非换行符作为行分隔符
--help 显示此帮助信息并退出
--version 显示版本信息并退出我们我们可以进行字符截取来实现信息的过滤,例如:

我们可以使用echo来打印信息,在打印的时候使用cut命令来筛选信息,例如上面过滤出第一个字符到第五个字符的信息。
我们在打印文件的时候是逐行过滤出信息的,如图:
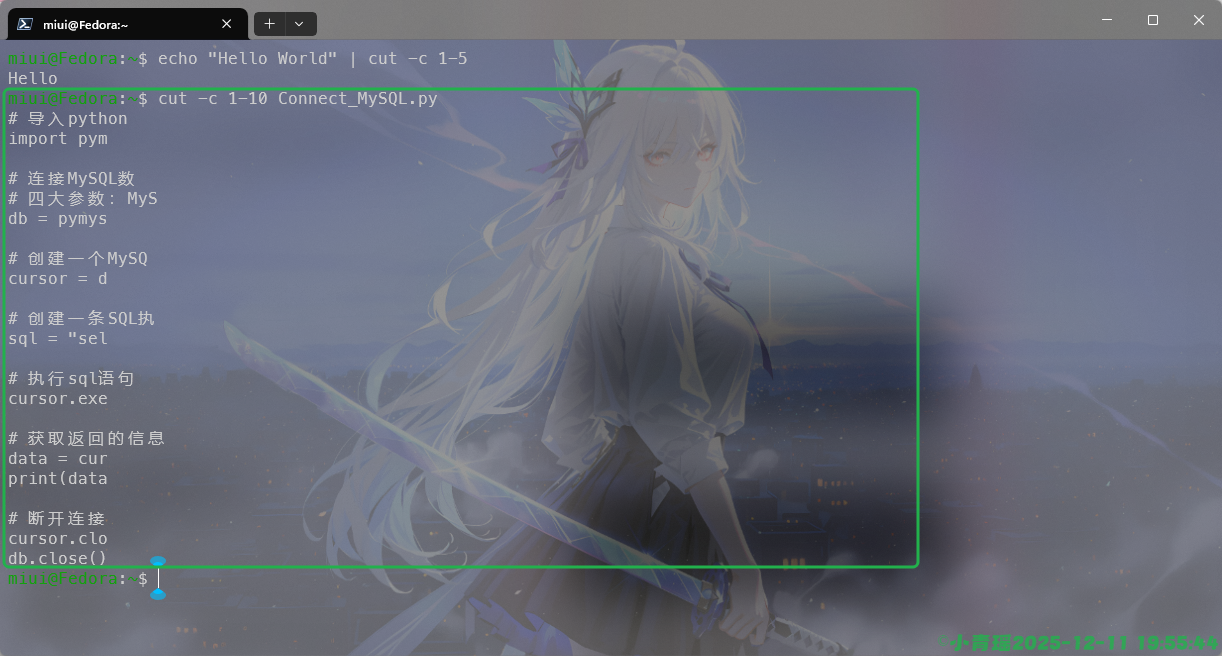
他会过滤出每一行的第1-10个字符的内容。
需要注意的是-b与-c的选项,一个是byte字节,一个是char字符,所以使用-b在打印的时候,过滤的是字节,不是字符,对比图如下:

虽然在打印英文字符的时候是一样的,但是在中文的时候就未必了。

假如文件是一个列表,如果是CSV文件,我们可以指定分隔符来进行过滤,如图:
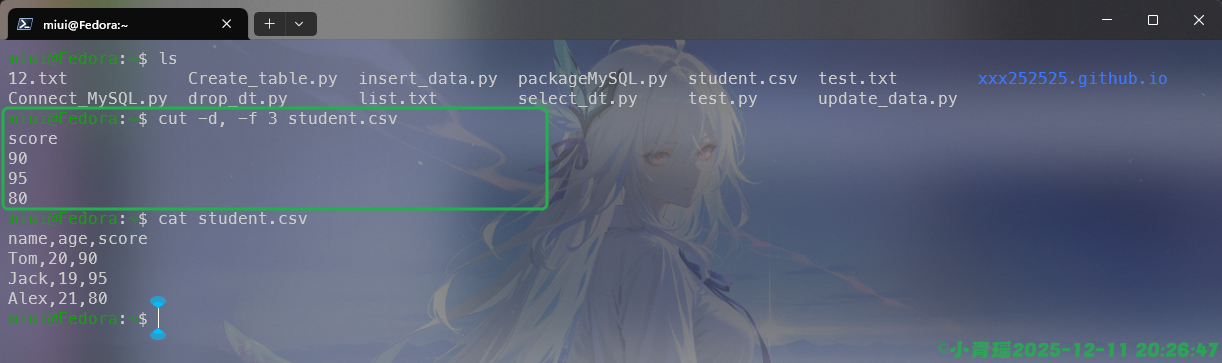
nl
nl命令主要是用于给文件内容自动添加行号,比cut -n更为灵活,可以控制行号的显示方式、宽度等。
语法:
nl [选项] [文件]
-b, --body-numbering=样式 使用 <样式> 对正文的行进行编号
-d, --section-delimiter=CC 使用 CC 作为逻辑页分隔符
-f, --footer-numbering=样式 使用 <样式> 对页脚的行进行编号
-h, --header-numbering=样式 使用 <样式> 对页眉的行进行编号
-i, --line-increment=数值 设置每一行行号的自动递增值
-l, --join-blank-lines=数值 将 <数值> 行连续的空行视为一行
-n, --number-format=格式 按照指定 <格式> 插入行号
-p, --no-renumber 在切换至下一节时不重置行号值
-s, --number-separator=字符串 在可能出现的行号后添加 <字符串>
-v, --starting-line-number=数值 每一节第一行的行号
-w, --number-width=数值 设置行号的宽度为 <数值> 列
--help 显示此帮助信息并退出
--version 显示版本信息并退出
所指定的 <样式> 是下列之一:
a 对所有行编号
t 仅对非空行编号
n 不对任何行编号
pBRE 仅对匹配基本正则表达式 BRE 的行编号
所指定的 <格式> 是下列之一:
ln 左对齐,无前导 0
rn 右对齐,无前导 0
rz 右对齐,有前导 0在默认的情况下我们使用nl命令查看文件内容的时候,只给非空编号,如图:
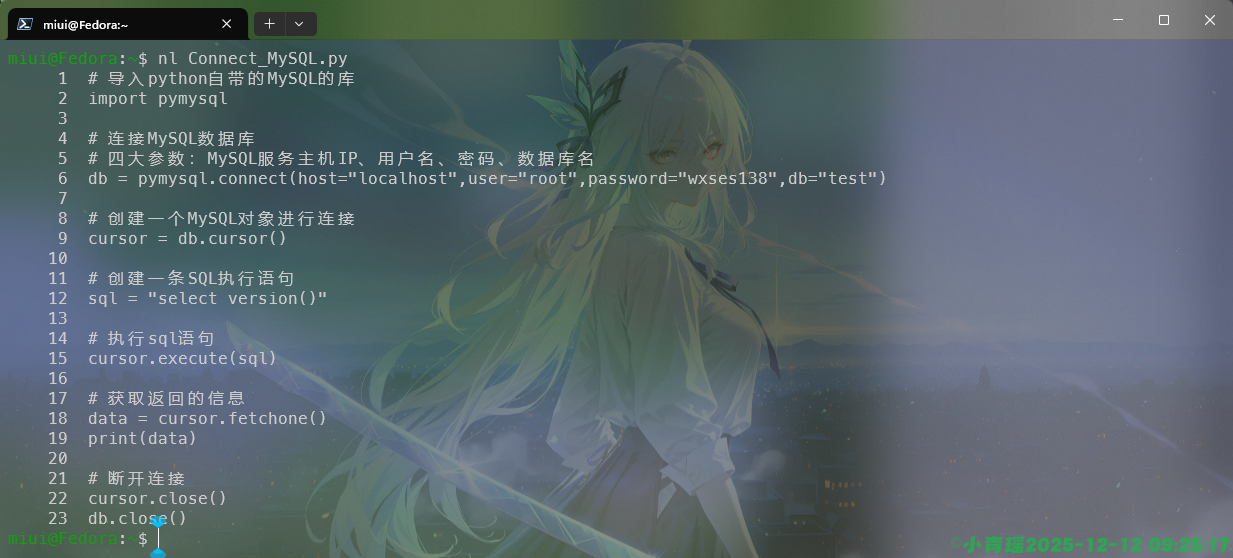
若要给所有行编号,包括空行,我们可以使用如下命令:
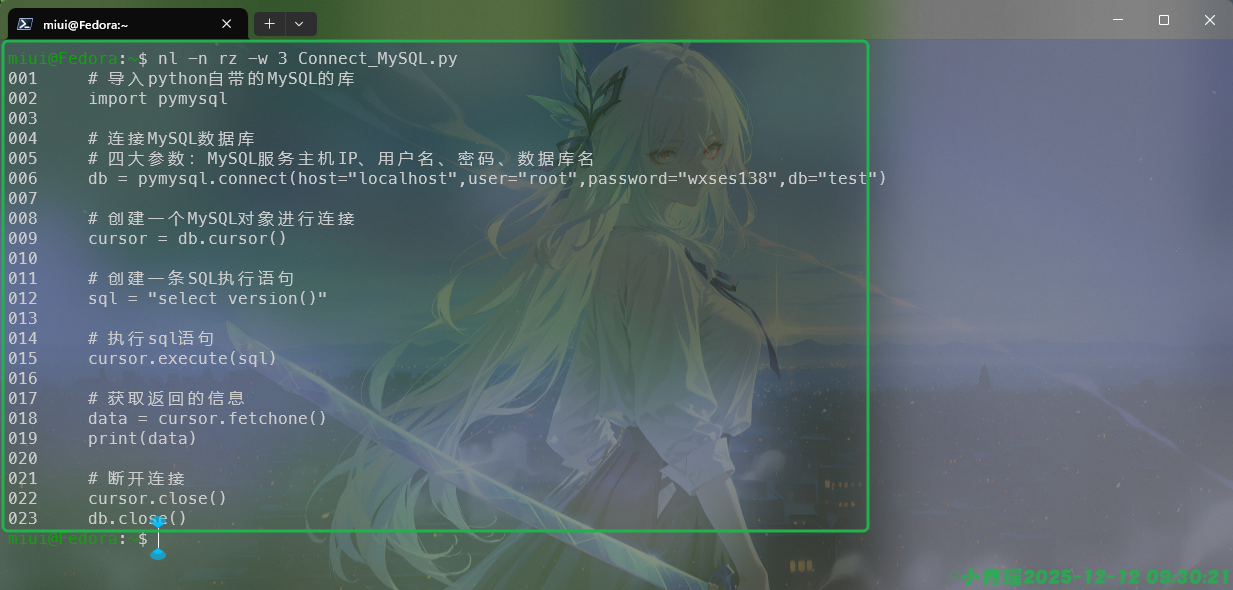
nl -b a 文件我们还可以使用行号右对齐,宽度为3,演示如下:
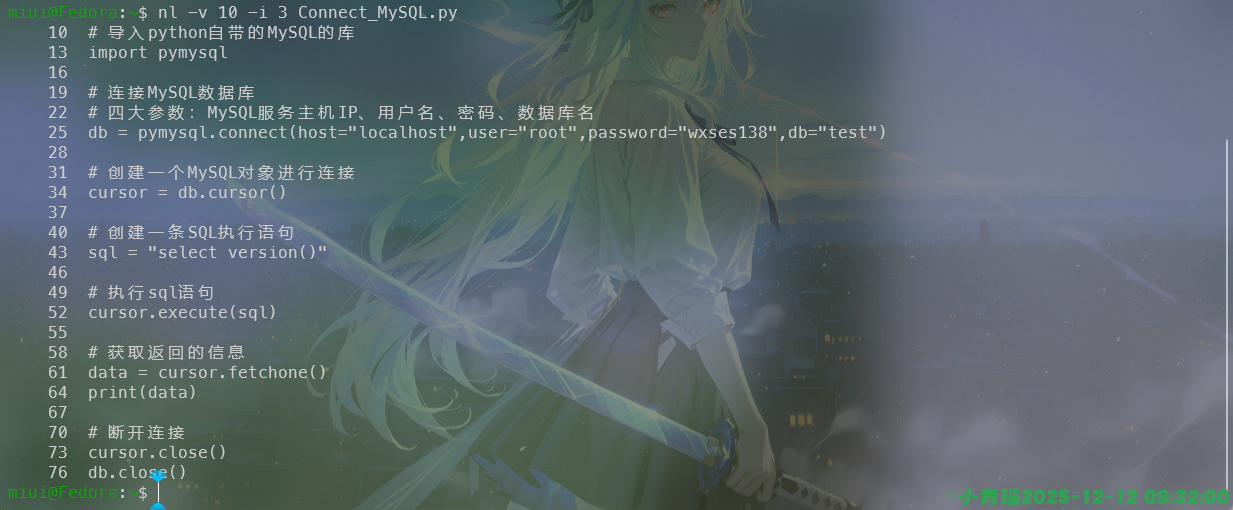
我们还可以从10开始编号,每次递增3个值,如图:
我们还可以使用-b来过滤出文件的信息,通过查找关键词,例如:

他只会对关键字出现的那一行去添加行号,方便我们去阅读信息。
uniq
uniq命令用于去除文件或者输入流中相邻的重复行,通常与sort搭配使用。
语法:
uniq [选项] [输入文件] [输出文件]
-c, --count 在每行之前加上该行的重复次数作为前缀
-d, --repeated 只输出重复的行,每组重复的行输出一次
-D 输出所有重复的行
--all-repeated[=方法] 类似 -D,但支持在每组重复的行之间添加一行空行;
方法={none(默认),prepend,separate}
-f, --skip-fields=N 不要比较前 N 个字段
--group[=方法] 分组输出所有项目,每组之间用空行分隔;
方法={separate(默认),prepend,append,both}
-i, --ignore-case 比较时忽略大小写
-s, --skip-chars=N 不要比较前 N 个字符
-u, --unique 只输出不重复(内容唯一)的行
-z, --zero-terminated 以 NUL 空字符而非换行符作为行分隔符
-w, --check-chars=N 每行最多比较 N 个字符
--help 显示此帮助信息并退出
--version 显示版本信息并退出默认情况下我们使用uniq命令的时候显示的文本内容会去除掉相邻的相同的信息,如图:

当我们使用-c选项的时候会进行一个次数的统计,如图:

我们还可以只显示重复行,使用-d即可,一般某些日志报错的时候会重复报错几次,例如:

只输出唯一的未重复行,操作如下:

重定向
在Linux中,存在输入重定向和输出重定向两个概念,输入重定向是用来改变命令的输入来源,也就是键盘;而输出重定向是改变命令输出的去向,也就是屏幕。
| 设备 | 设备文件名 | 文件描述符 | 类型 |
|---|---|---|---|
| 键盘 | /dev/stdin | 0 | 标准输入 |
| 显示器 | /dev/stdout | 1 | 标准输出 |
| 显示器 | /dev/stdeer | 2 | 标准错误输出 |
输入重定向
command < file将文件的内容作为命令的输入,而不是键盘。
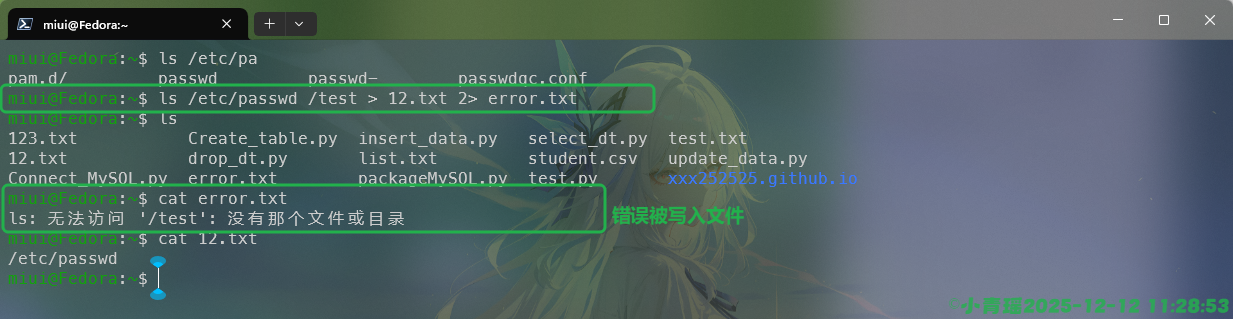
假如我们要统计文件的行数,使用<来实现输入的重定向,此时文件作为一个命令被输入,而不是一个文件,如图:

如果是一个文件,在使用之后会返回文件的名称,但是将文件内容作为命令输入的时候是没有的。
常用的重定向符号如下:
| 符号 | 说明 | 案例 |
|---|---|---|
| < | 输入来自文件 | cat < file.txt |
| > | 输出覆盖写入文件 | ls > file.txt |
| >> | 输出追加写入文件 | echo “char” >> file.txt |
| 2> | 错误输出重定向 | ls /no 2 > file.txt |
| << | 内联输入 | cat << EOF … EOF |
| 2>&1 | 错误输出合并到标准输出 | cat > file.txt 2>&1 |
内联输入command << delimiter,我们在脚本命令中直接输入内容,内容会被写入,直到遇到结束符号才算完毕。内联输入是把一段文本作为命令输入,用于命令的执行,批量生成文件等。

我们搭配cat命令查看内容,也可以通过使用输出重定向来实现文件的写入。
我们还可以结合其他的命令去使用去执行一些临时性的工作。例如执行一些数据库的操作:
mysql -u root -p << EOF
CREATE DATABASE test;
Use test;
CREATE TABLE users(id, nam, value)
EOFEOF包裹的内容会在登陆数据库之后进行一个执行。
输出重定向
输出重定向就是将键盘的输出写入到文件,用屏幕显示。
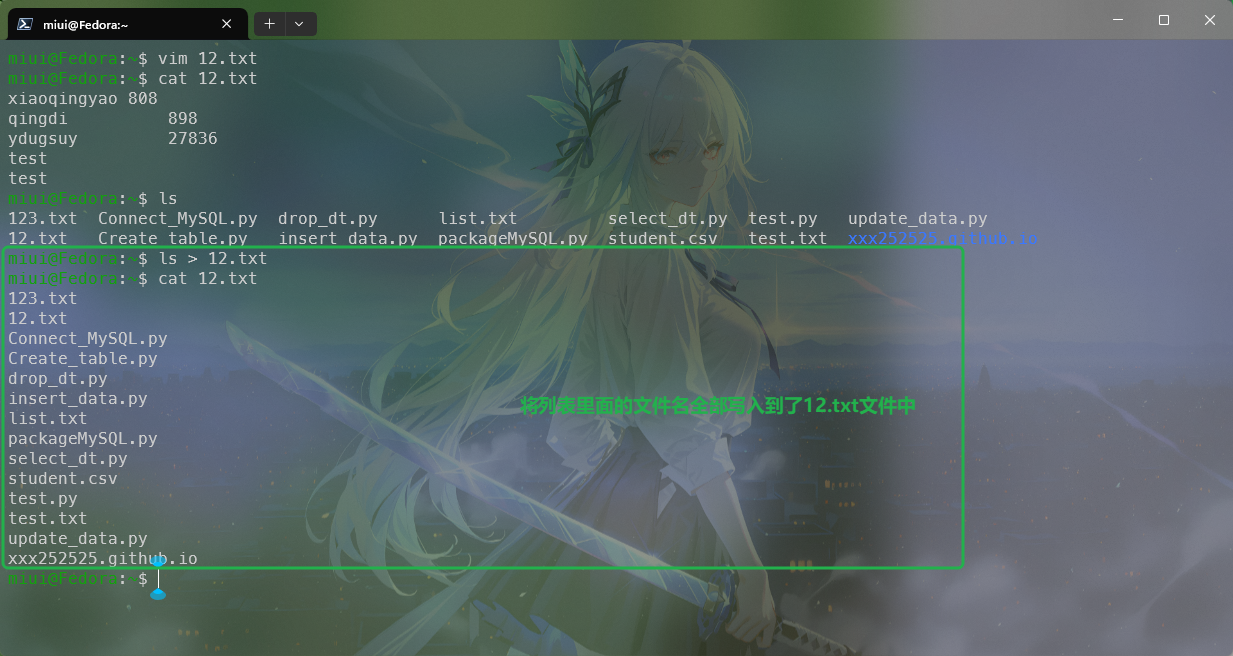
command > file.txt可以将输出写入到文件中,覆盖掉原有的所有内容。如图所示:
如果只想在文件中增加内容,而不进行覆盖,我们只需要使用>>即可,如图:
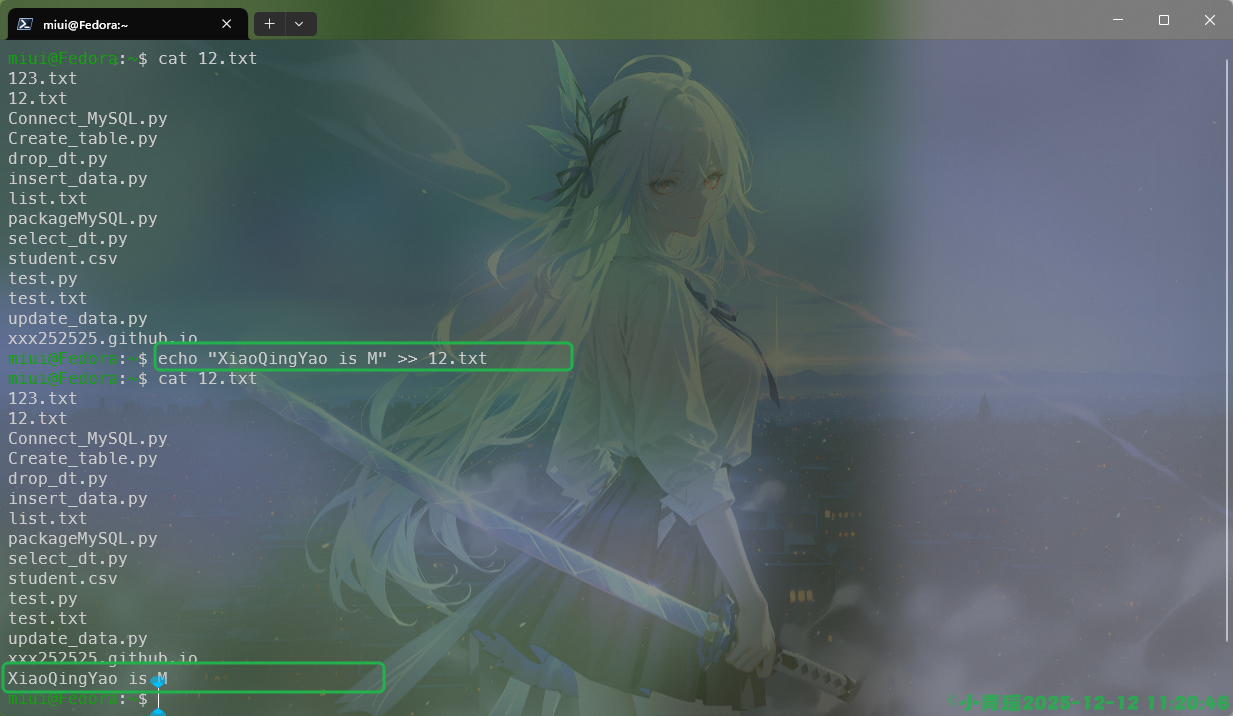
我们也可以将错误的信息写入文件,这个时候需要用到2>,报错的信息将会被写入文件:
我们还可以把正确和错误的信息合并在一个文件中,使用2>&1来实现,当然大多数情况下肯定是分开的

Here Document
Here Document是一种重定向技术,前面的内联输入就使用的是该重定向技术。
语法:
commmand << DELIMITER
内容...
DELIMITERDELIMITER是自定义的结束语,常见的写法就是EOF。
我们通过输入输出重定向搭配使用,可以实现更为复杂的文件写入和命令执行的操作。
最常见的就是我们去修改一些配置文件,例如修改如下脚本:


重要
如果我们在进行某些变量操作的时候,变量可能会被替换,这个时候只需要在重定向符号之后的EOF上加上单引号即可,否则变量会被替换。
如果要进行缩进控制,比如严格的代码规范,可以使用<<-来忽略前面的Tab,方便控制缩进。
链接文件
在Linux操作系统中有类似于Windows一样的快捷方式,但是又不完全相同。链接是一种在共享文件和访问它的用户录项之间建立联系的方法。我们使用ln命令来创建链接。
Linux中的链接主要分为软链接和硬链接。
硬链接(hard link)是指通过索引l节点(inode)来进行连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(inode index)。多个文件名指向同一索引节点是存在的。硬链接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止误删。因为对应该目录的索引节点有一个以上的连接,所以只删除一个连接并不影响索引节点本身和文件数据。
软链接(symbolic link),类似于Windows系统中的快捷方式。它实际上是一个指针或一个路径名,而不是实际的文件。当软链接指向的原始文件被删除时,软链接本身也就变得无效了。软链接可以对文件、目录、跨文件系统的文件或目录创建文件的软链接。
警告
注意软硬链接的区别:
- 硬链接像是文件的多个“化身”,它们共享同一个内容,不能跨文件系统,删除所有硬链接才会真正删除文件。
- 软链接更像是一个指向文件的“快捷方式”或“纸条”,可以跨文件系统,但如果原文件被删除,软链接就失效了。
语法:
ln [选项]... [-T] 目标 链接名
ln [选项]... 目标
ln [选项]... 目标... 目录
ln [选项]... -t 目录 目标...
第一种格式,创建一个名为 <链接名> 的、指向 <目标> 的链接。
第二种格式,在当前目录创建指向 <目标> 的链接。
第三和第四种格式,在 <目录> 中创建指向各个 <目标> 的链接。
默认创建硬链接,当使用 --symbolic 时创建符号链接。
默认情况下,目标(指新链接的名称)不能已经存在。
创建硬链接时,每个 <目标> 都必须存在。符号链接可以包含任意的文本;
以后进行解析时,符号链接会被解析为一个相对于其父目录的相对链接。
--backup[=控制] 为每个已存在的目标文件创建备份文件
-b 类似 --backup,但不接受参数
-d, -F, --directory 允许超级用户尝试创建指向目录的硬链接
(注意:即使是超级用户,此操作也可能因系统
限制而失败)
-f, --force 删除已存在的目标文件
-i, --interactive 删除目标文件前进行确认
-L, --logical 如果 <目标> 为符号链接,将其解引用
-n, --no-dereference 如果 <链接名> 是一个指向目录的
符号链接,则将其视为普通文件处理
-P, --physical 创建直接指向符号链接的硬链接
-r, --relative 和 -s 同时使用时,创建相对于链接位置的链接
-s, --symbolic 创建符号链接,而不是硬链接
-S, --suffix=后缀 替换通常使用的备份文件后缀
-t, --target-directory=目录 在指定的 <目录> 中创建链接
-T, --no-target-directory 总是 <链接名> 视为普通文件
-v, --verbose 打印每个已创建链接的文件名称
--help 显示此帮助信息并退出
--version 显示版本信息并退出请看下面的案例:
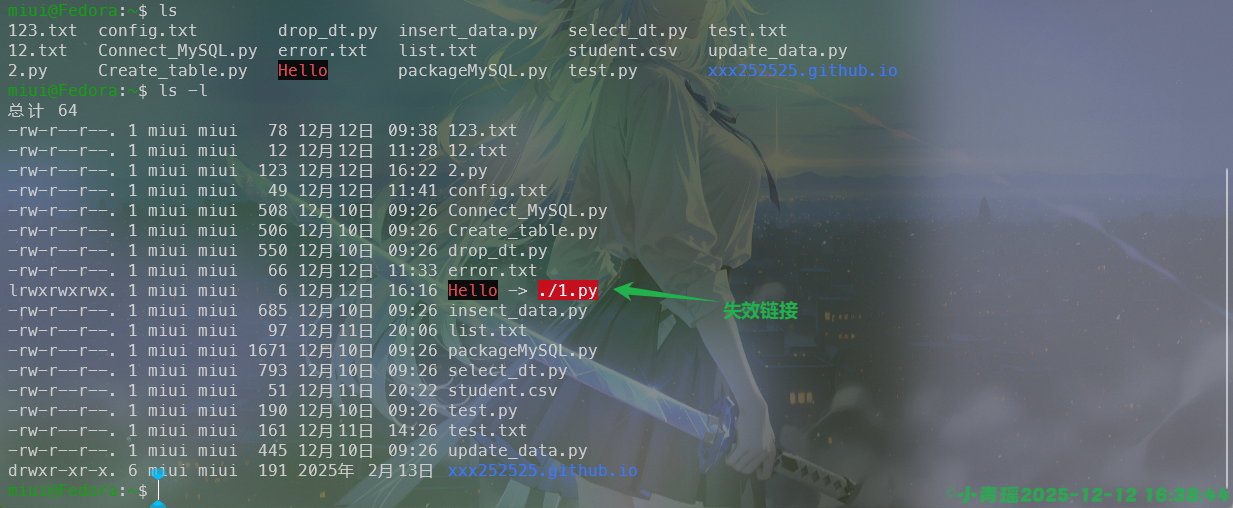
我们创建一个1.py文件,然后给这个文件创建硬链接,名为hello,操作如下:
miui@fedora:~$ touch 1.py
miui@fedora:~$ ln ./1.py ./hello
miui@fedora:~$ ls
1.py 模板 图片 下载 桌面 main.cpp project test2 test4 test.jar test.js test.py
公共 视频 文档 音乐 hello main.py test1 test3 test.cpp test.java test.php test.sh
miui@fedora:~$ ll hello 1.py
-rw-r--r--. 2 miui miui 0 2月20日 16:42 1.py
-rw-r--r--. 2 miui miui 0 2月20日 16:42 hello我们再来为1.py文件创建一个软链接,操作如下:
miui@fedora:~$ ln -s ./1.py ./Hello
miui@fedora:~$ ll hello 1.py Hello
-rw-r--r--. 2 miui miui 0 2月20日 16:42 1.py
-rw-r--r--. 2 miui miui 0 2月20日 16:42 hello
lrwxrwxrwx. 1 miui miui 6 2月20日 16:44 Hello -> ./1.py可以看见我们的硬链接编程了一个独立的文件,而软链接是一个符号链接,指向文件1.py,前面的文件符号也发成了变化,硬链接是文件符号-,而软链接是链接符号l。
我们使用vim来编辑下1.py里面的内容,重新创建一个硬链接2.py,然后修改2.py的内容,并且参看两个文件内容区别:
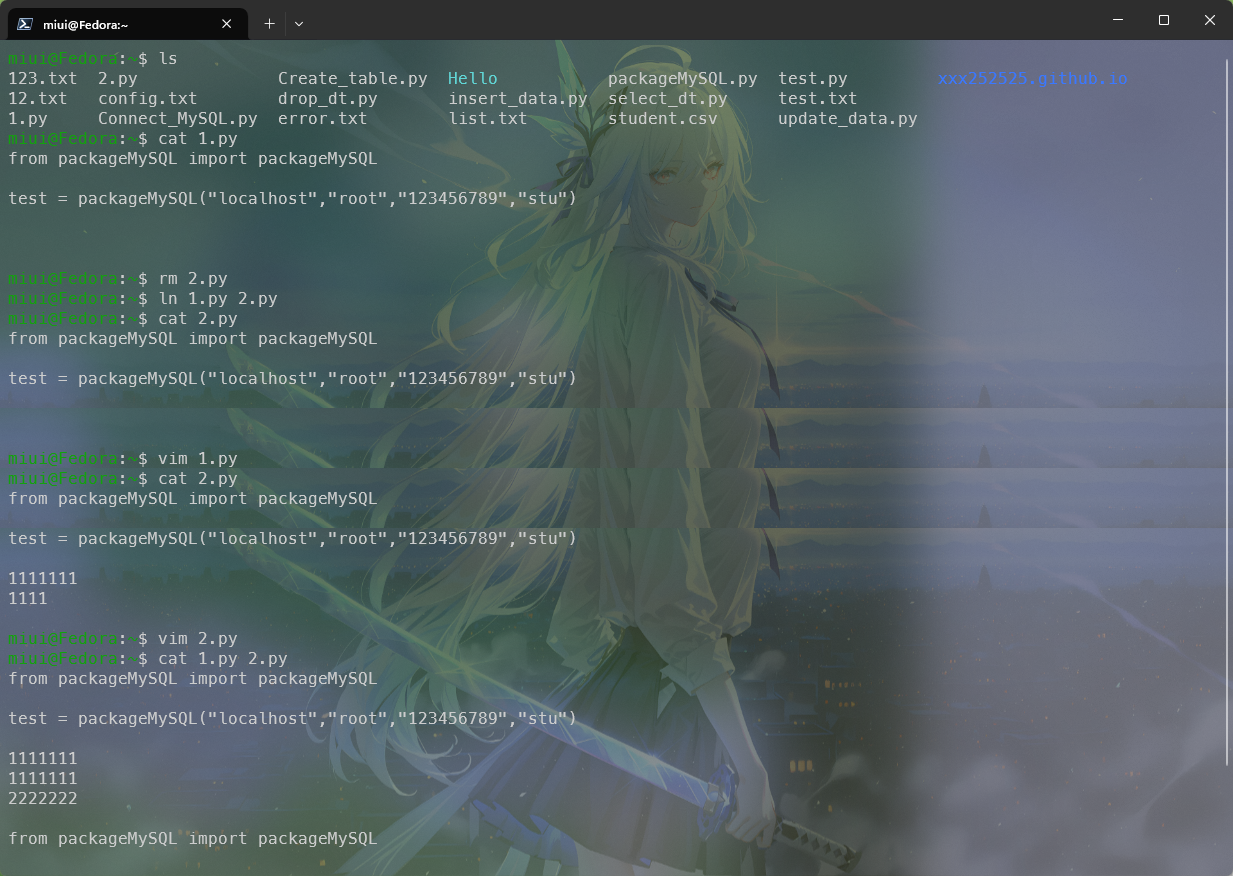
可以看见,硬链接2.py与1.py是内容是共通的,编辑任何一个文件,另外一个文件都会随着同步。当原始文件被删也不会对创建的硬链接内容造成影响,如图:
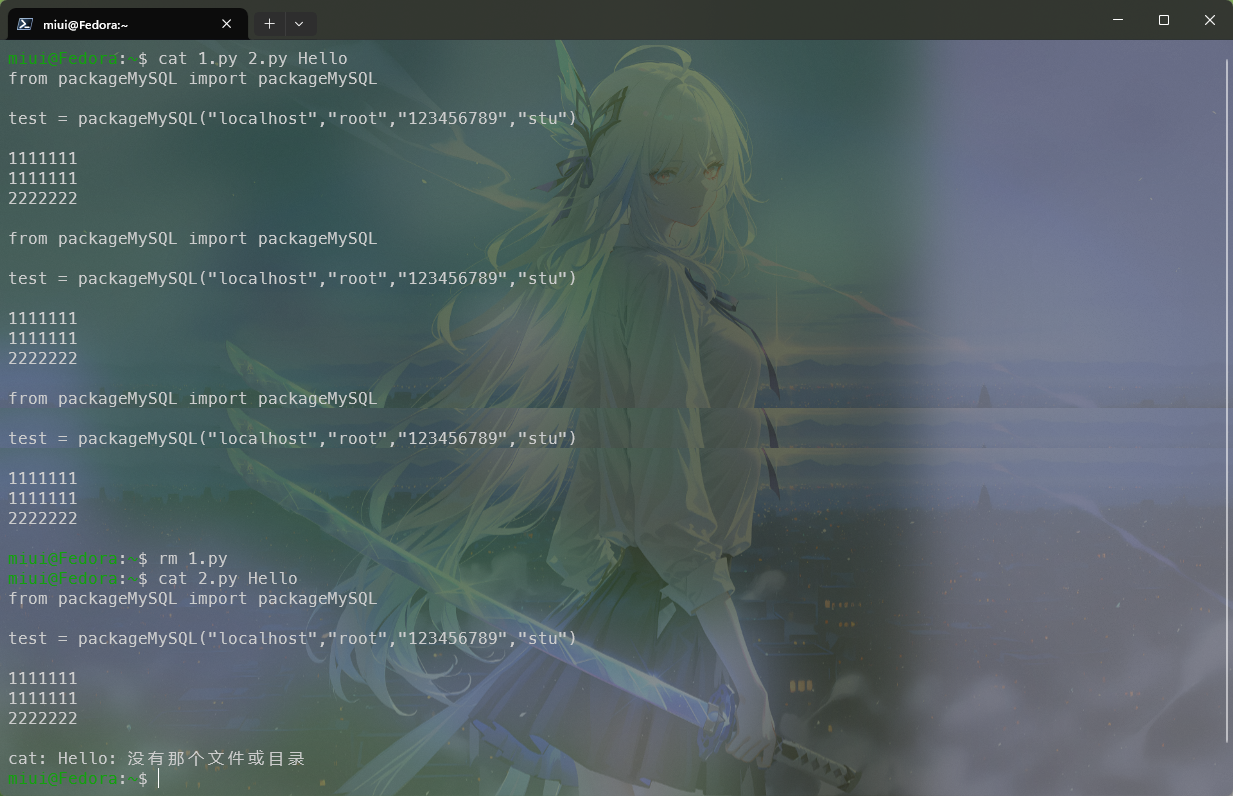
硬链接不能跨文件系统,而软链接可以。硬链接的数量有限制,因为它们共享inode,而软链接没有这个限制。删除原文件后,硬链接依然有效,而软链接会变成无效链接(broken link)。
特性对比表:
| 特点 | 硬链接 | 软链接 |
|---|---|---|
| 指向对象 | inode(文件本体) | 文件路径 |
| 是否跨文件系统 | 不可以 | 可以 |
| 是否能链接目录 | 一般不可 | 可以 |
| 原文件删除影响 | 不影响 | 链接失效 |
| 文件大小 | 与原文件一样 | 很小 |
| 权限与属性 | 共享原文件属性 | 链接自身有属性,访问按照原文件权限 |
正则表达式
正则表达式是用于描述字符排列和匹配模式的一种语法规则,它主要用于字符串的模式分割、匹配、查找及替换操作。
正则表达式与通配符
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed等命令可以支持正则表达式。通配符用来匹配符合条件的文件名,通配符是完全匹配。s、find、cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配了。
通配符
| 通配符 | 说明 |
|---|---|
| * | 匹配前一个字符任意次数 |
| . | 匹配任意单个字符(换行除外) |
| + | 前一个字符至少出现一次 |
| ? | 前一个字符可有可无 |
| ^ | 匹配行的开始 |
| $ | 匹配行的结束 |
| [] | 匹配括号中的任意字符 |
| [^] | 不匹配括号内的字符 |
| 前一个字符精确m次 | |
| 表示前面的字符不少于m次 | |
| 限制次数,m到n | |
| () | 分组,将多个字符视为一个整体 |
| ` | 或 |
| \ | 转译,匹配特殊字符 |
| [abc] | 匹配固定字符内容abc |
| [a-z] | 匹配小写字母 |
| [A-Z] | 匹配大写字母 |
| [^0-9] | 匹配非数字内容 |
| [0-9] | 匹配数字集合 |
| | | 匹配两个或者多个分支选择 |
案例:
miui@Fedora:~$ mkdir test
miui@Fedora:~$ cd test/
miui@Fedora:~/test$ touch abc acb aaa bcd
miui@Fedora:~/test$ ls
aaa abc acb bcd
miui@Fedora:~/test$ touch abce acb aaae bcdk cba
miui@Fedora:~/test$ ls
aaa aaae abc abce acb bcd bcdk cba
miui@Fedora:~/test$ find . -name abc
./abc
miui@Fedora:~/test$ find . -name abc?
./abce
miui@Fedora:~/test$ find . -name "abc*"
./abc
./abce
miui@Fedora:~/test$注意,在使用通配符的时候尽量添加一个引号,避免错误。
正则表达式多与其他命令搭配使用实现一些文件的处理,案例操作将在下面的grep命令中实现更多。
文件处理三剑客
grep
grep命令是Linux中用于搜索文本内容的工具,通常与正则表达式配合使用过滤出关键的信息。
语法:
grep [选项] [文件]
模式选择与解释:
-E, --extended-regexp <模式> 是扩展正则表达式
-F, --fixed-strings <模式> 是字符串
-G, --basic-regexp <模式> 是基本正则表达式
-P, --perl-regexp <模式> 是 Perl 正则表达式
-e, --regexp=模式 使用指定的 <模式> 进行匹配
-f, --file=文件 从指定的 <文件> 中获得 <模式>
-i, --ignore-case 对于模式和数据,忽略大小写
--no-ignore-case 不要忽略大小写(默认)
-w, --word-regexp 仅匹配整个单词
-x, --line-regexp 仅匹配整行
-z, --null-data 数据行以 0 字节 (NUL) 结束,而非换行符
-s, --no-messages 不显示错误信息
-v, --invert-match 选中不匹配的行
-V, --version 显示版本信息并退出
--help 显示此帮助信息并退出
-L, --files-without-match:仅打印那些没有包含被选中行的文件的名称。
-l, --files-with-matches:仅打印那些包含被选中行的文件的名称。
-c, --count:仅打印每个文件中被选中行的数量。查找包含关键字的行:
取反操作,我们使用-v选项来过滤出不包括关键字的内容,如图:

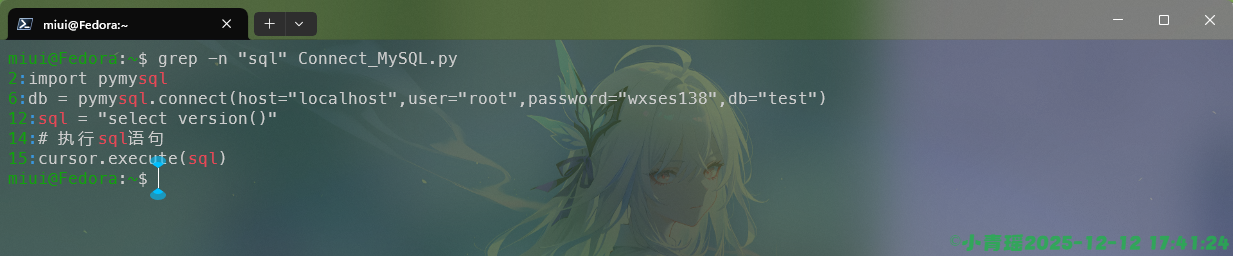
我们可以通过使用-n选项来显示行号,快速找到文件错误的地方,如图:
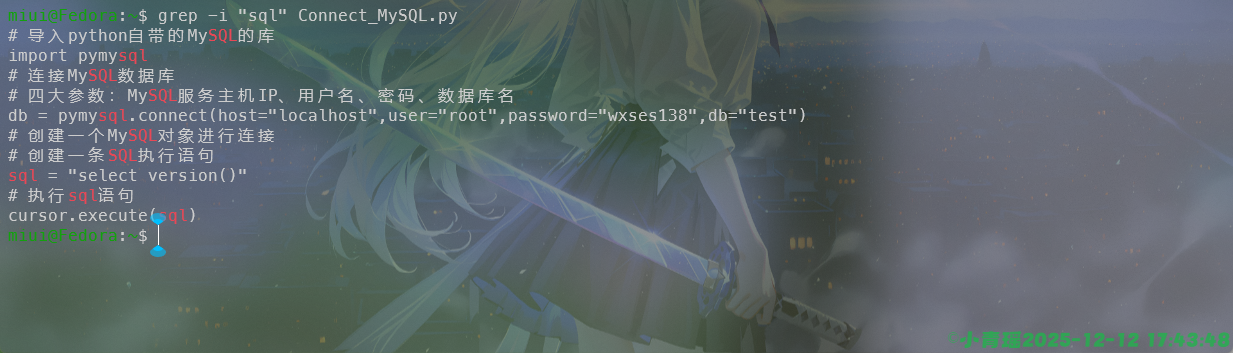
默认是过滤掉大小写的,需要忽略大小写可以使用-i选项,如图:
使用-o选项进行精准筛选,只显示匹配到的内容,如图:

grep的强大远不止这一些,我们还可以实现搜索多个文件中的内容,如图:

递归搜索目录,我们需要使用-r选项来实现,如图:
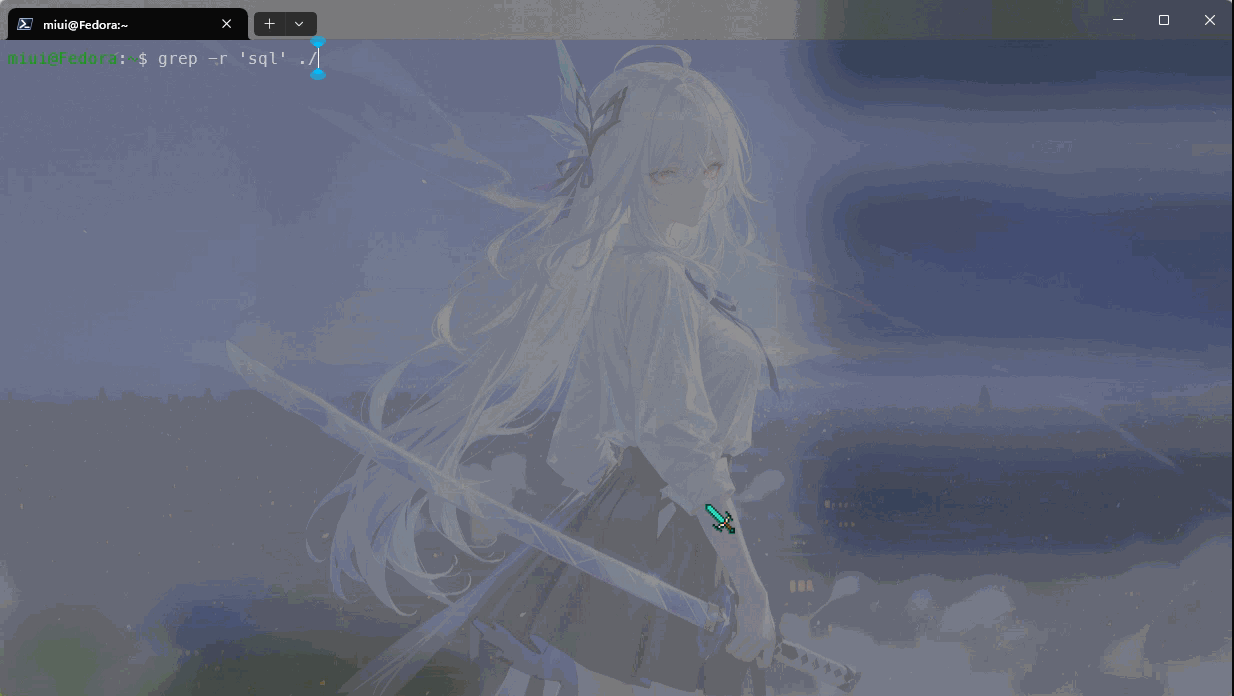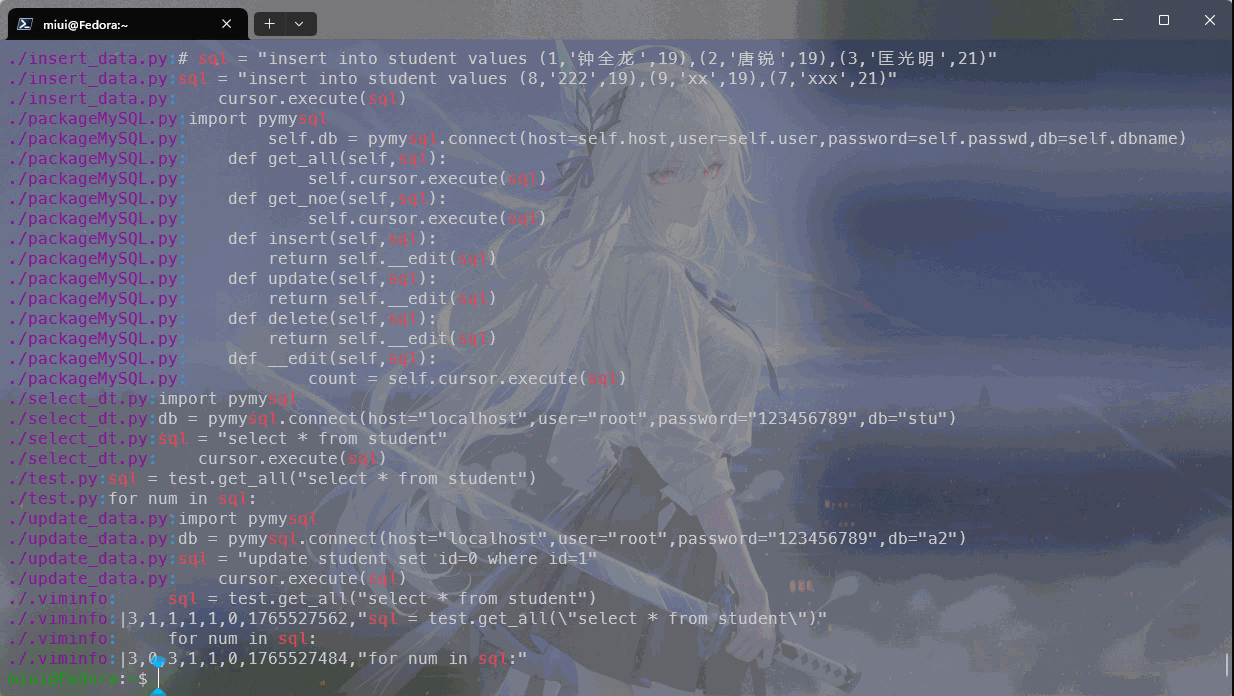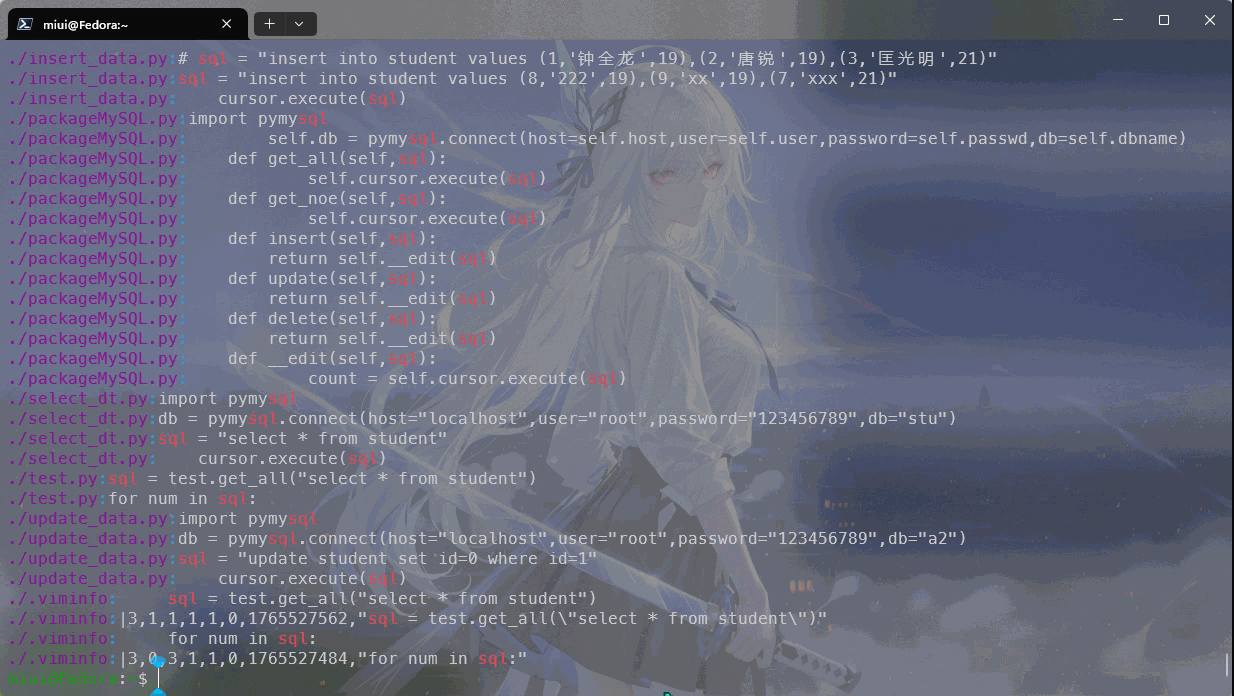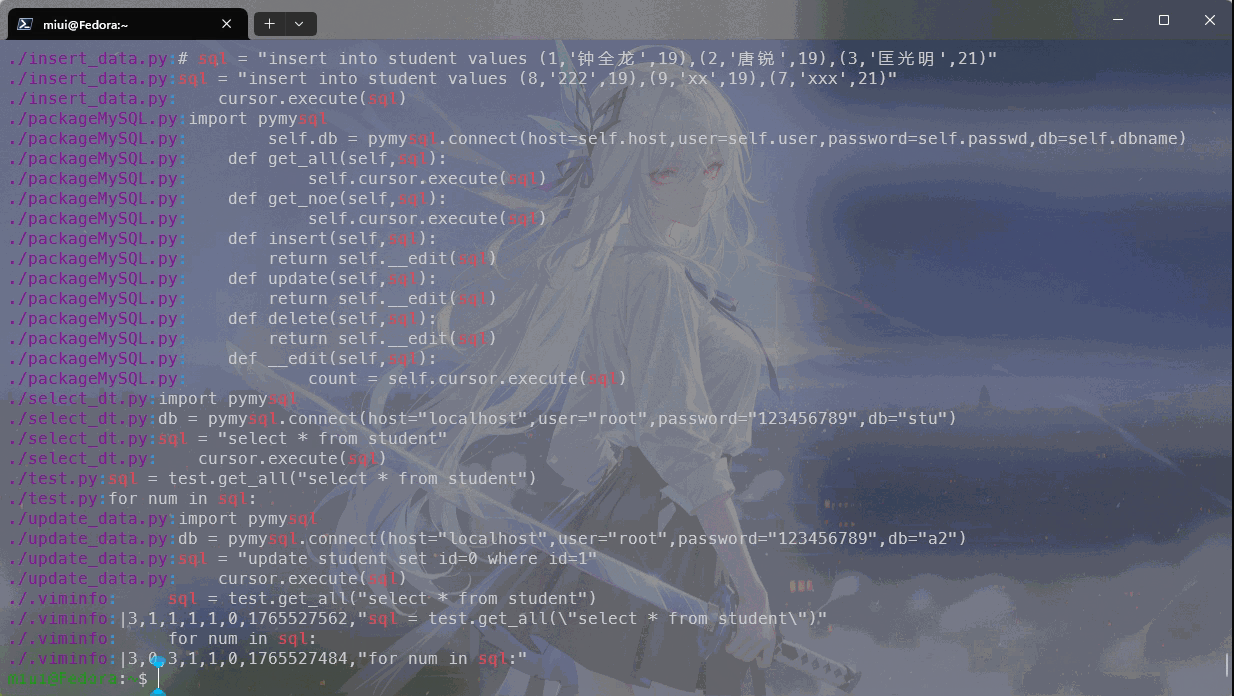
我们通常还会使用到精准匹配,这些在帮助我们阅读一些繁琐较长的日志的时候是很有帮助的,使用-w选项来精确匹配,如图:

统计匹配行数的时候使用-c选项即可,

还可以通过文件内容来筛选出文件,含有关键字的文件都可以查找过滤出来,如图:
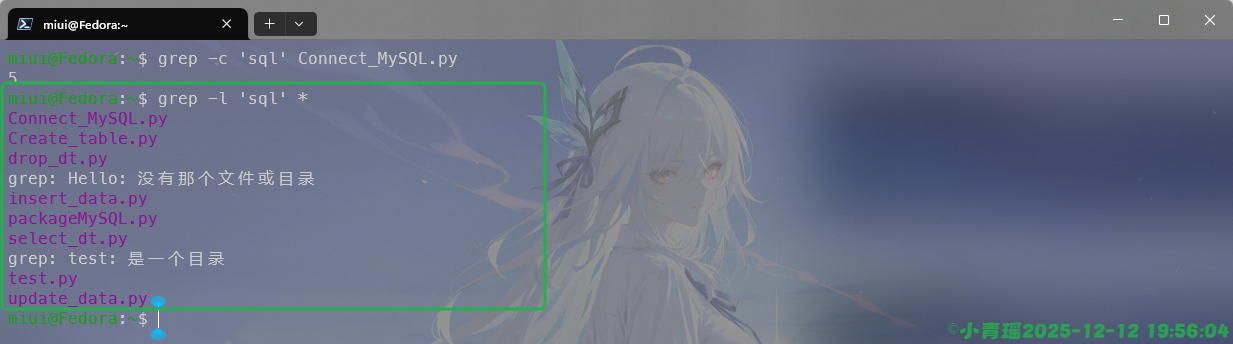
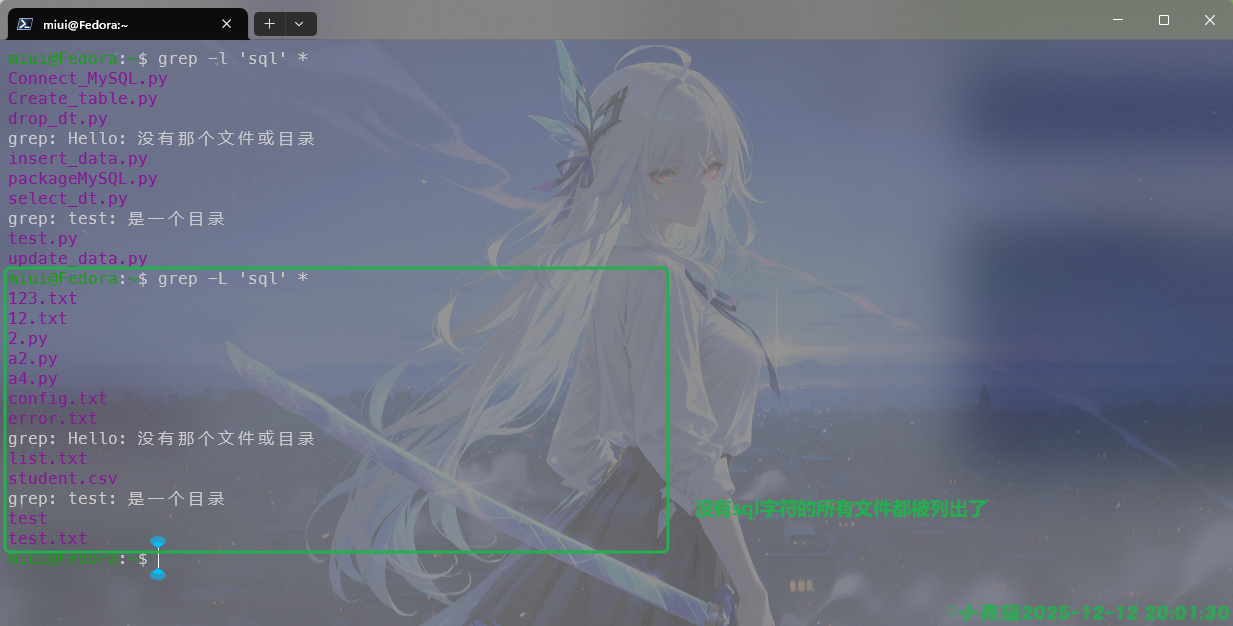
如果我们要反向操作,只需要将-l修改为-L即可,如图:
扩展正则表达式
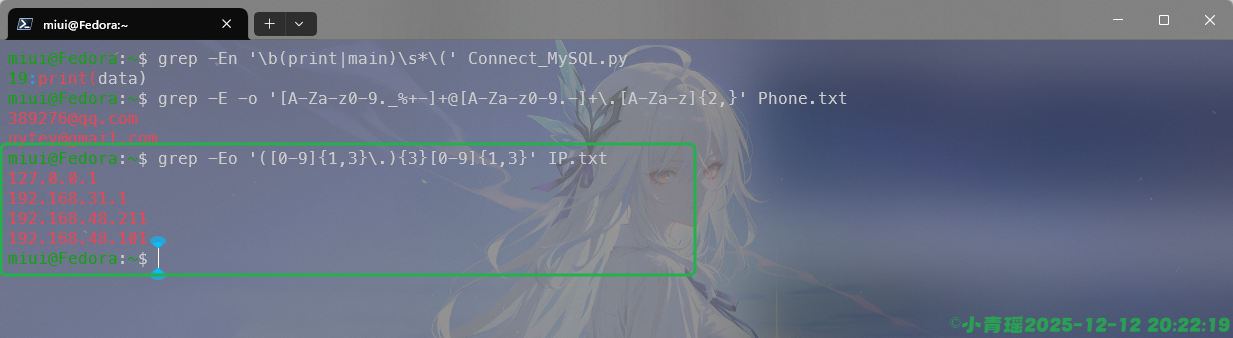
匹配两个关键词中的任何一个,操作如下:

匹配函数的调用,这里是允许空格的演示操作:

邮箱匹配操作如下:

简单的IPV4匹配操作如下:
文件处理是很核心的内容,可以继续深究以下正则表达式与扩展正则表达式在实际中的用途。
awk
awk是按照行、列、条件进行文本处理的语言,非常适合用于条件过滤、统计求和、格式化输出等操作。在处理日志文件和CSV文件、配置文件等结构性文件上有很大的优势。
语法:
awk '模式{动作}' 文件
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-D[file] --debug[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-i includefile --include=includefile
-I --trace
-l library --load=library
-L[fatal|invalid|no-ext] --lint[=fatal|invalid|no-ext]
-M --bignum
-N --use-lc-numeric
-n --non-decimal-data
-o[file] --pretty-print[=file]
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-s --no-optimize
-S --sandbox
-t --lint-old
-V --version --version这里的模式就是条件,可以是正则表达式,动作是对匹配的行进行什么样的操作。
使用-o选项查看文件的内容,我们这里使用正则表达式来实现和cat一样的效果阅读文件的内容,如图:

awk默认情况下使用空格或者制表符来作为分隔符的,每一列使用$num表示,整行num就是0。-F <空格符>指定字段分隔符,使用的是空格。
内置变量
| 变量 | 含义 |
|---|---|
| $0 | 当前整行 |
| $1, ,,n,, | 第n个字段 |
| NF | 当前行字段数 |
| NR | 当前行号 |
| FS | 输入分隔符 |
| OFS | 输出字段分隔符,默认是空格 |
| RS | 输入记录分隔符,默认换行 |
| FNR | 当前文件的行号 |
| ORS | 输出记录分隔符 |
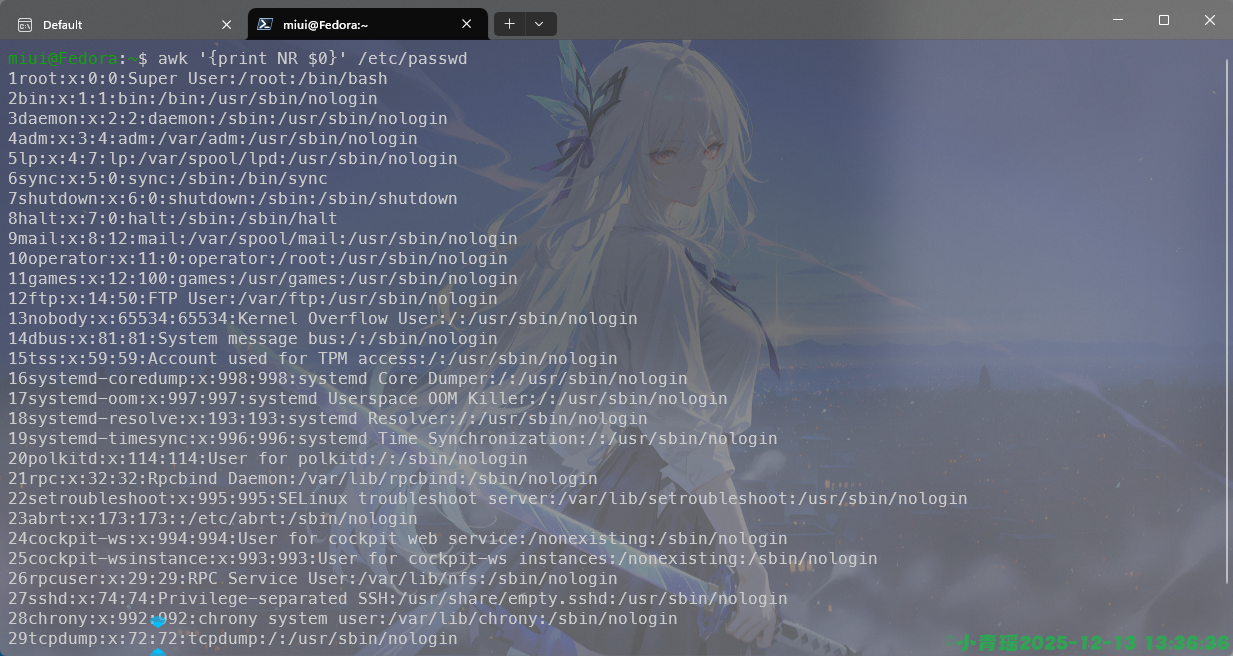
比如打印第一列和第二列的信息,例如/etc/passwd文件的信息过滤出第一行第七行的信息,如图:
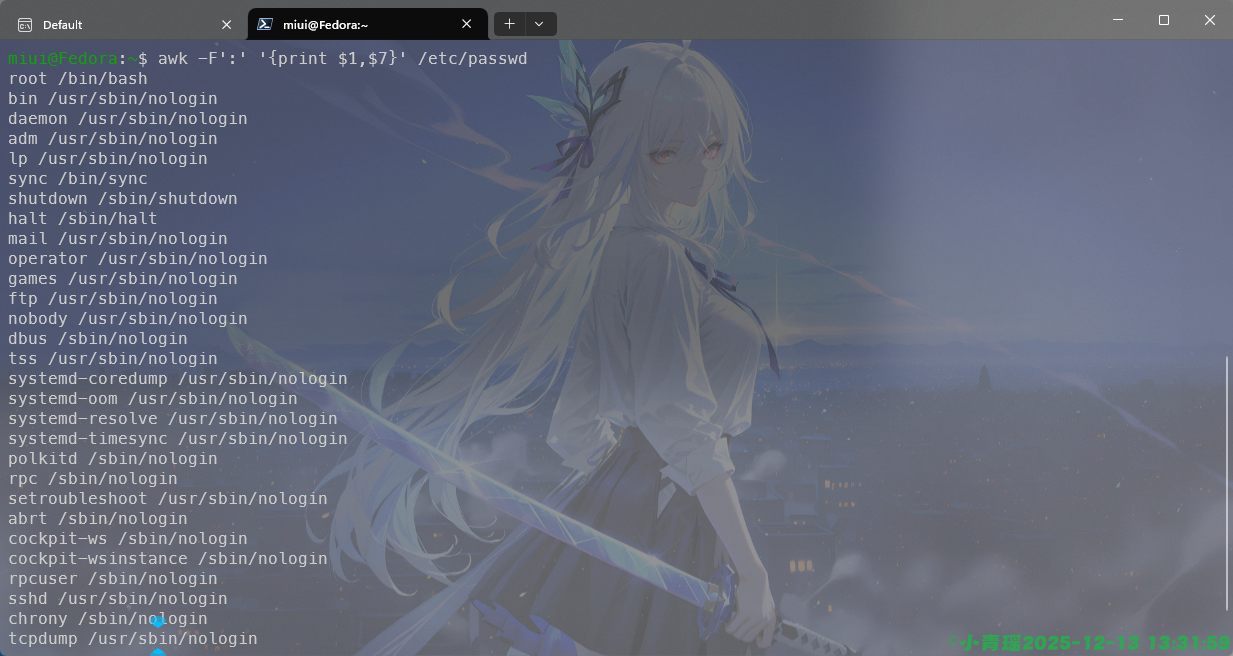
由于passwd文件下面的格式是user:???:???:…:/path,所以我们需要使用-F选项来指定分隔符为‘:’来实现信息的过滤。
我们还可以在打印内容的时候显示行号,如图:
在检查错误日志的时候多会使用到条件匹配,如图操作:
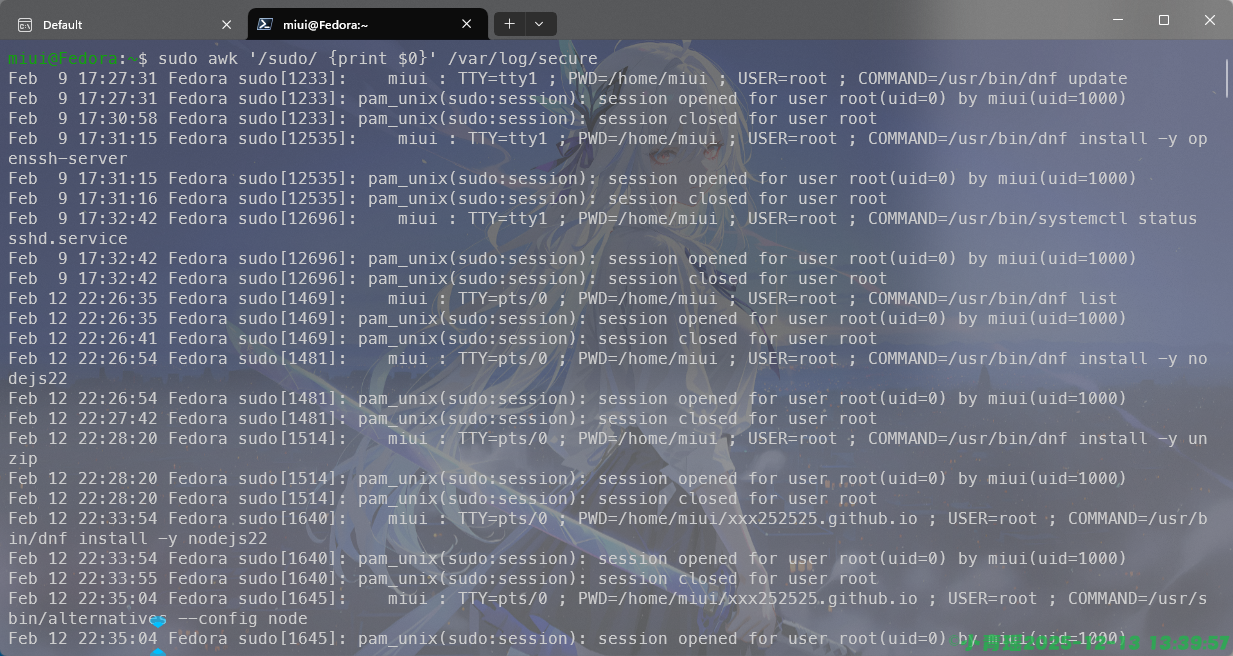
我们过滤出提权的操作,也就是带有sudo的操作信息。
BEGIN-END
BEGIN是读文件前执行一次,ENG是处理完成之后执行一次。由于没有案例文件,这里给出示例代码即可:
awk 'BEGIN {print "start"}
{sum += $1}
END {print sum}' file.txt同时awk还可实现求和、平均值和计数等操作,求和操作如下:
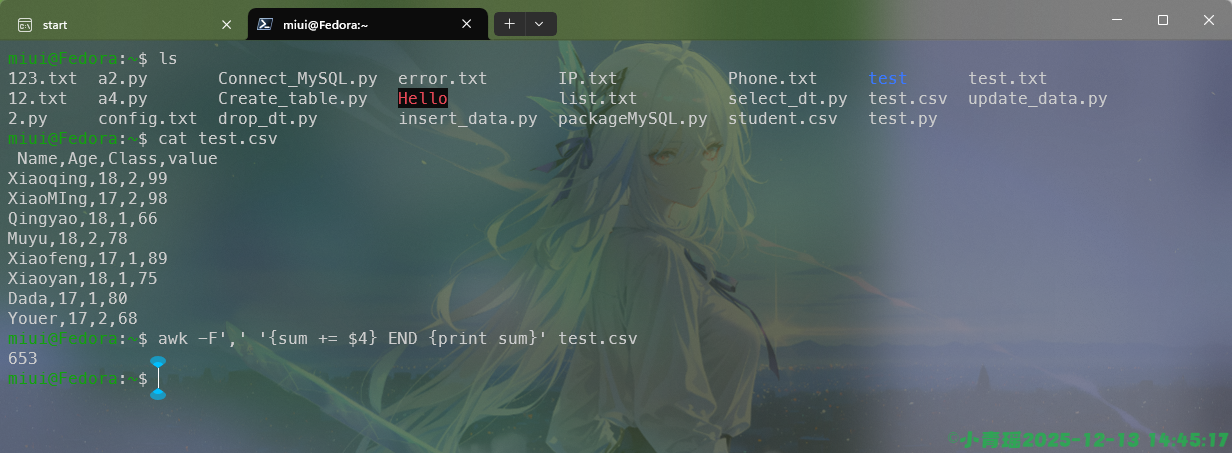
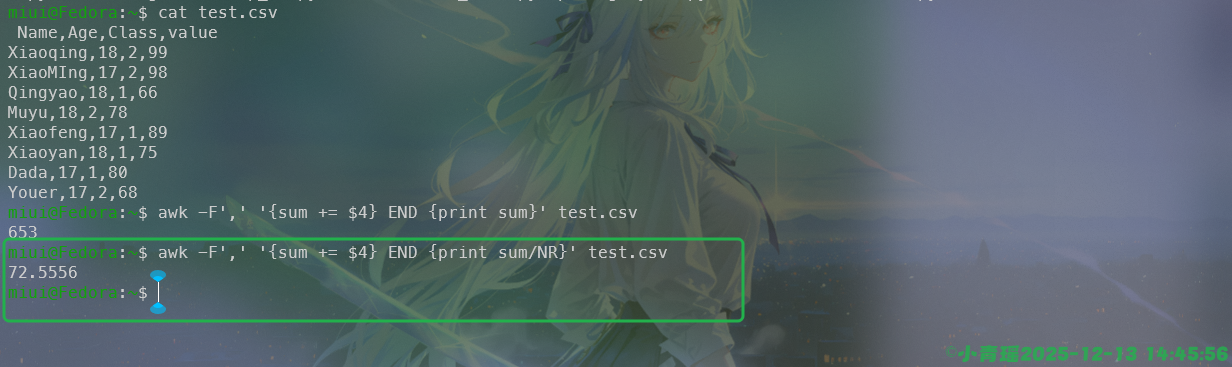
求平均值如下:
1️⃣ 统计 value 总和
awk -F, 'NR>1 {sum+=$4} END{print sum}' test.csv
2️⃣ 求平均值
awk -F, 'NR>1 {sum+=$4; n++} END{print sum/n}' test.csv
3️⃣ 只统计 Class=1 的 value
awk -F, 'NR>1 && $3==1 {sum+=$4} END{print sum}' test.csv
4️⃣ 打印 Name + value
awk -F, 'NR>1 {print $1, $4}' test.csvawk还可以实现格式化输出,使用printf,格式化输出一般用于shell编程中,编写脚本的时候混合使用。

一些小实战如下:
1、找出登录 shell 是 bash 的用户

2、统计端口监听数量

3、打印每行最后一列

4、交换两列

5、第一列去重
awk '!a[$1]++' file数组
awk 的数组是“关联数组(哈希表)”,不是下标数组也就是说:下标不是只能是数字,可以是:字符串、IP、用户名、字段内容等,非常适合做 统计、去重、分组。
语法:
arr[key] = value计数型数组
awk '{count[$1]++} END {for (k in count) print k, count[k]}' file这里的count计数,$1作为Key,出现一次就加1,最后遍历输出。
去重数组
awk '!seen[$1]++' file第一次出现:seen[$1] 为 0 → 输出;第二次开始:值 ≥1 → 不输出
分组统计
awk '{sum[$1] += $2} END {for (k in sum) print k, sum[k]}' file统计每个用户的总流量、总分数等。
数组 + 条件,例如统计成绩大于60的次数
awk '$2 > 60 {score[$1]++} END {for (i in score) print i, score[i]}' file数组 + 多字段,多字段作为 key(拼接),常用于:IP + 端口,用户 + 日期
awk '{key = $1 "-" $2; count[key]++}
END {for (k in count) print k, count[k]}' file数组排序,按 key 排序(GNU awk)
awk '{count[$1]++}
END {
n = asorti(count, sorted)
for (i=1; i<=n; i++)
print sorted[i], count[sorted[i]]
}' file按照value排序
awk '{count[$1]++}
END {
n = asort(count, sorted)
for (i=1; i<=n; i++)
print sorted[i]
}' file实战案例
统计每个 IP 出现次数
awk '{ip[$1]++} END {for (i in ip) print i, ip[i]}' access.log查找访问最多的IP
awk '{ip[$1]++}
END {
max=0
for (i in ip)
if (ip[i] > max) {max=ip[i]; maxip=i}
print maxip, max
}' access.logIP去重
awk '!seen[$1]++' access.log统计日志中每种状态码
awk '{code[$9]++}
END {for (c in code) print c, code[c]}' access.logawk完整意义上能算一门小编程语言,学习的内容很多,需要深度训练与掌握。
sed
sed可以在不打开文件,不进入交互界面来实现文本的篡改,是一种高级的流编辑器。适合批量替换内容,删除行、插入新内容,格式处理等。
语法:
sed [选项]... {脚本(如果没有其他脚本)} [输入文件]...
-n, --quiet, --silent
取消自动打印模式空间
--debug
对程序运行进行标注
-e 脚本, --expression=脚本
添加“脚本”到程序的运行列表
-f 脚本文件, --file=脚本文件
添加“脚本文件”到程序的运行列表
--follow-symlinks
直接修改文件时跟随软链接
-i[扩展名], --in-place[=扩展名]
直接修改文件(如果指定扩展名则备份文件)
-c, --copy
use copy instead of rename when shuffling files in -i mode
-b, --binary
does nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX
(open files in binary mode; CR+LF are not processed specially)
-l N, --line-length=N
指定“l”命令的换行期望长度
--posix
关闭所有 GNU 扩展
-E, -r, --regexp-extended
在脚本中使用扩展正则表达式
(为保证可移植性使用 POSIX -E)。
-s, --separate
将输入文件视为各个独立的文件而不是单个
长的连续输入流。
--sandbox
在沙盒模式中进行操作(禁用 e/r/w 命令)。
-u, --unbuffered
从输入文件读取最少的数据,更频繁的刷新输出
-z, --null-data
使用 NUL 字符分隔各行
--help 打印帮助并退出
--version 输出版本信息并退出最常见的操作就是sed 's/旧的内容/新内容/选项' 文件。
我们经常使用s来实现文本的替换
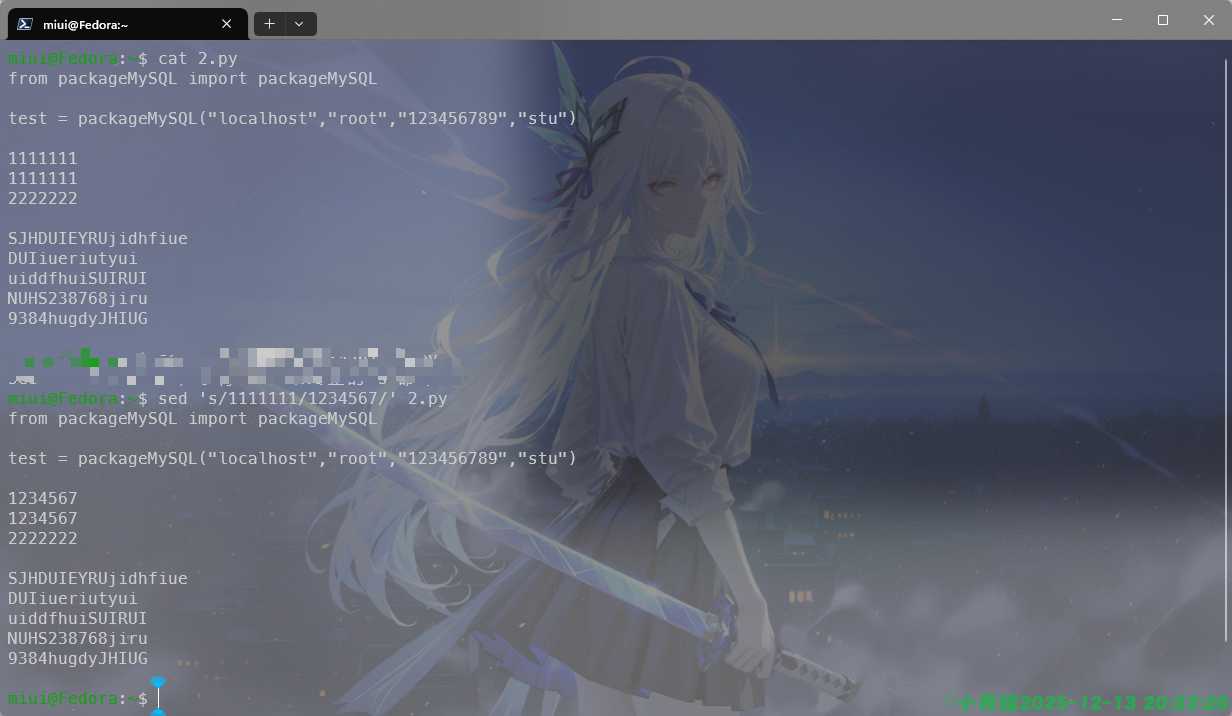
使用d来实现内容的删除,如图:
注意我们这个时候是无法修改内容的,虽然打印出来的内容变了,但是实际的内容并没有变,需要彻底修改原文件,需要添加-i选项。

使用-n选项和p搭配可以打印具体的内容信息,比如第三行到第六行的信息,如图:

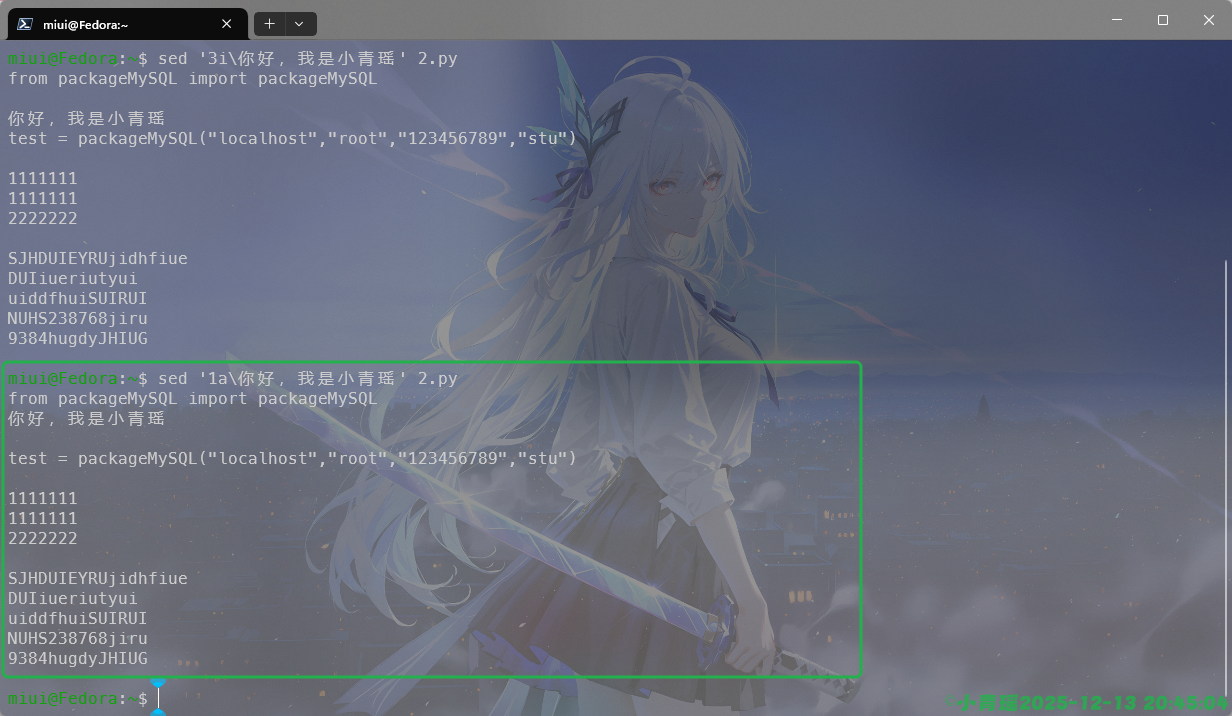
i的作用就是插入,在第几行进行插入,插入什么信息,如图:

我们还可以实现内容的追加,在行的后面,而不是前面进行插入,如图:
来实现一个替换整行的操作,如图:
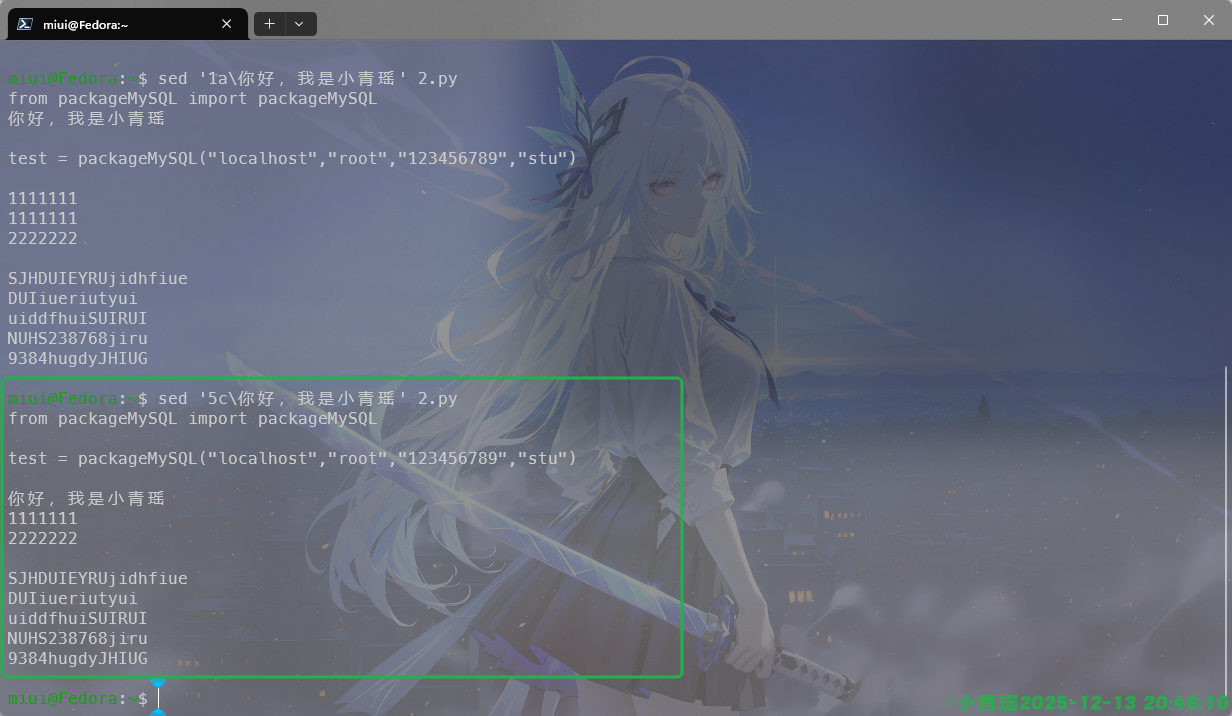
警告
注意写入文件一定要使用选项-i
组合正则
sed默认使用的是基础的正则表达式,使用扩展正则表达式需要使用-E选项。
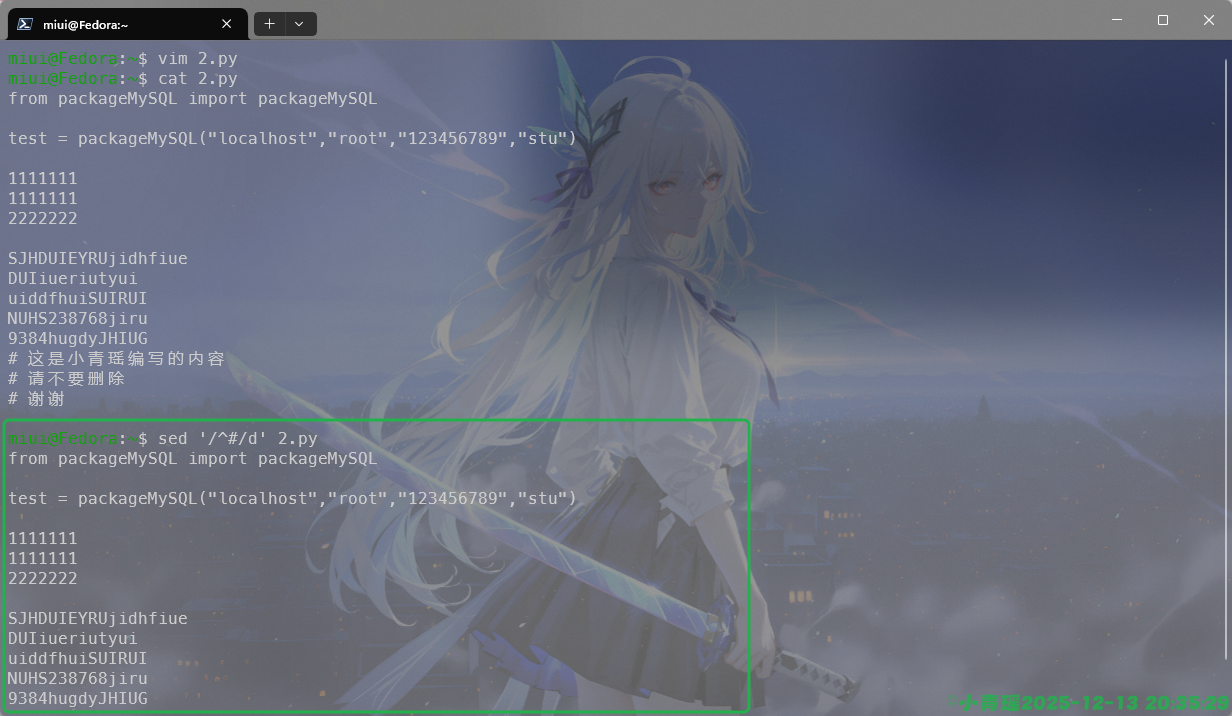
例如删除空行的操作:

我们还可以批量替换配置选项,操作如下:
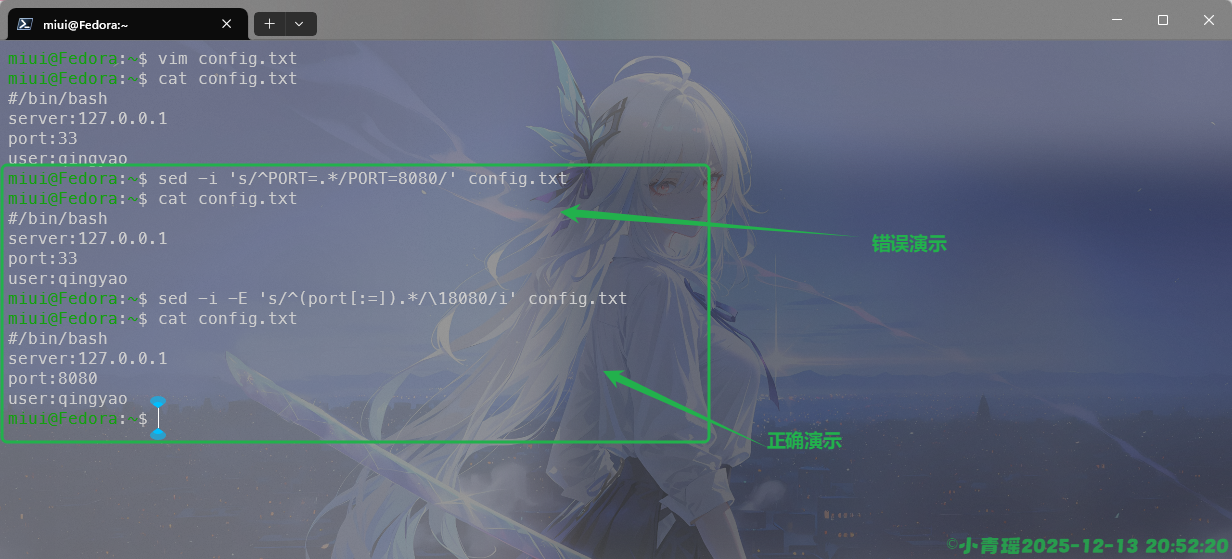
我们需要注意的是使用扩展正则表达式会更安全一点,括号内的[:=]意思就是冒号或者登号,\1保留原来的分隔符,使用i来忽略大小写,其实正常情况下配置文件基本上全是大写,很少有小写字母的,因为演示文件的随意编写而导致的错误干扰。
其他演示示例代码:
# 去掉行首空格
sed 's/^[ \t]*//' file
# 文件内容编号
sed = file | sed 'N;s/\n/ /'
# 只替换第 N 次匹配
sed 's/foo/bar/2' file
在匹配行后追加内容
sed '/mysql/a\# MySQL config' file| 工具 | 做什么 |
|---|---|
| grep | 找“行”(过滤) |
| sed | 改“文本”(替换、删除) |
| awk | 玩“列 + 逻辑 + 统计” |
用一句话来概括就是grep找、sed改、awk算
打赏
如果觉得文章写的还不错,可以给作者一个小小的支持嘛?请我喝杯蜜雪冰城可好?

